MLPerf 1.1에서 IPU-POD16, ResNet-50 모델 훈련 28.3분 기록
인공지능(AI) 반도체 기업 그래프코어가 최신 MLPerf 1.1 벤치마크 테스트에서 자사의 IPU(Intelligence Processing Unit) 시스템이 기록적인 성능을 달성했다고 밝혔다.
이에 회사 측은 “규모가 점차 확대되면서 효율성과 성능, 소프트웨어 성숙도는 물론 사용 편의성이 꾸준히 향상되고 있는 그래프코어 IPU 시스템의 경쟁력을 다시한번 입증했다”고 평가했다.
.jpg) 페브리스 모이잔 글로벌 세일즈 부사장
페브리스 모이잔 글로벌 세일즈 부사장
그래프코어는 9일, 온라인 기자간담회를 갖고 최신 IPU-POD 시스템과 MLPerf 벤치마크 테스트 결과를 발표하고, 국내 AI 혁신 가속화를 위한 그래프코어의 계획과 국내 사업 성과 및 방향성 등에 대해 소개했다.
그래프코어 IPU 시스템은 지속적인 소프트웨어 최적화를 통해 향상된 성능을 제공하고 있다. 특히, 이번 MLPerf 벤치마크에서 그래프코어 IPU-POD16은 컴퓨터 비전 모델 ResNet-50 훈련에 있어 엔비디아의 DGX A100을 능가하는 성능을 보였다고 밝혔다.
ResNet-50을 훈련하는데 엔비디아 DGX A100은 29.1분이 걸린데 반해, 그래프코어의 IPU-POD16은 28.3분을 기록했다는 것. 이는 소프트웨어만으로 첫 MLPerf 테스트 결과 대비 24%의 성능 향상을 이룬 것으로, 통상적으로 ResNet-50 모델 학습에 GPU가 사용되고 있다는 점을 감안하면 이번 결과는 더욱 주목할 만하다고 강조했다.
그래프코어는 또한 최근 새롭게 출시된 IPU-POD128 및 IPU-POD256에 대한 벤치마크 결과도 공개했다. 그래프코어는 MLPerf '상용화 가능(Commercially Available)' 부문에 해당 시스템에 대한 테스트 결과를 제출하며 지속적인 시스템 규모 확대 및 성능 향상을 위한 노력을 증명했다. 그래프코어 IPU 시스템 상 역대 최고의 성능을 자랑하는 IPU-POD128과 IPU-POD256의 경우 ResNet-50 모델 훈련에 걸린 시간은 각 5.67분, 3.79분에 불과했다.
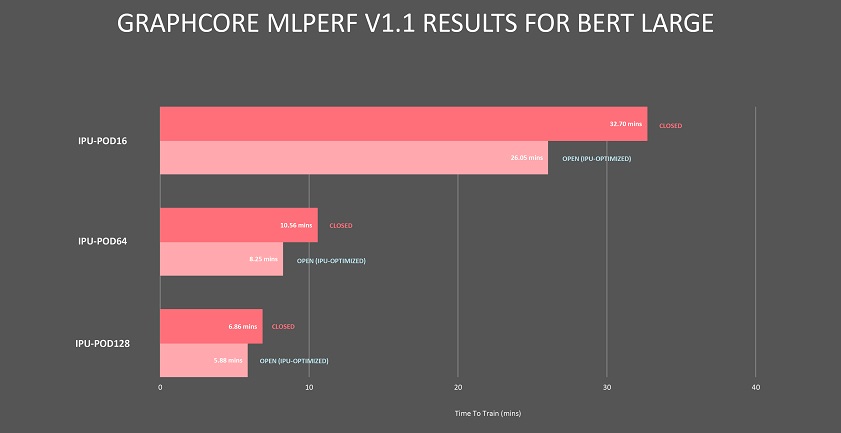 전반적으로 BERT 모델 훈련 성능은 지난 MLPerf 벤치마크 대비 IPU-POD16은 5%, IPU-POD64는 12%가 각각 향상됐다.
전반적으로 BERT 모델 훈련 성능은 지난 MLPerf 벤치마크 대비 IPU-POD16은 5%, IPU-POD64는 12%가 각각 향상됐다.
자연어 처리(NLP) 모델 BERT의 경우, 그래프코어는 IPU-POD16, IPU-POD64 및 IPU-POD128 훈련 데이터를 오픈(Open) 및 클로즈드(Closed) 부문 모두에 제출했다. 특히 오픈 부문에서 최신 IPU-POD128의 훈련 시간은 5.78분으로 월등한 성능을 보였다. 전반적으로 BERT 모델 훈련 성능은 지난 MLPerf 벤치마크 대비 IPU-POD16은 5%, IPU-POD64는 12%가 각각 향상됐다.
이 밖에도, 그래프코어의 플래그십 제품 IPU-POD256은 EfficientNet B4 모델 훈련에 대해 단 1.8시간을 기록하며 실질적인 성능적 이점의 가능성을 보여주기도 했다.
호스트 서버와 AI 컴퓨팅을 분리하는 등 시스템 설계 단계에서부터 업계 내 다른 기업들과는 근본적으로 다른 ‘혁신적 접근’을 취해온 그래프코어는 최소 3개월마다 성능 향상을 위한 소프트웨어 업데이트를 진행하고 있으며, IPU를 위한 새로운 모델 및 워크로드를 구현하고 최적화하는 작업을 수행하고 있다.
<저작권자(c)스마트앤컴퍼니. 무단전재-재배포금지>