



글 | 마이크 산타리니 (Mike Santarini) 자일링스 Xcell 저널 발행인
버텍스-7 H580T 디바이스는 업계 최고 대역폭을 구현하기 위해 자일링스의 적층형 실리콘 인터커넥트(SSI) 기술을 사용해 최대 16개의 28 Gbps 트랜스시버와 72개의 13.1 Gbps 트랜스시버가 단 하나의 칩 솔루션으로 통합되어 Nx100G와 400G 라인 카드 솔루션을 위한 대역폭과 신호 무결성을 실현한다.
자일링스는 28 nm 버텍스-7(Virtex짋-7) 2000T(업계 최초의 3D 적층형 실리콘 인터커넥트 stacked-silicon interconnect 기술을 갖춘 28 nm FPGA)를 출시하면서 용량과 트랜지스터 수에 대한 기록을 새롭게 갱신한데 이어, 지난 5월 SSI 기술을 이용한 디바이스를 발표함으로써 FPGA 대역폭에 대한 기록도 갈아치웠다. 새로운 버텍스-7 H580T 디바이스는 단일 실리콘 상의 FPGA 다이에 집적한 2개의 트랜시버와 함께 전용 8-채널 28 Gbps 트랜시버 슬라이스(다이)를 통합하고 있다. 이 새로운 제품은 모두 최대 48개의 13.1 Gbps 트랜시버는 물론, 8개의 28 Gbps 트랜시버, 580,480개의 로직 셀을 갖춘 디바이스를 유선통신 기업들에게 제공한다. 버텍스-7 H580T FPGA는 주요 2x100G 애플리케이션 및 기능을 해결할 수 있는 단일 칩 솔루션이다(그림 1 참조).
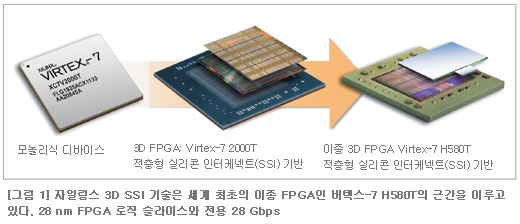
자일링스의 첨단 통신 부문 시니어 디렉터인 에프렘 우(Ephrem Wu) 씨는 “자일링스의 100 Gbps 기어박스와 이더넷 MAC, OTN, 인터라켄 IP(Interlaken IP)를 모두 갖추고 있는 버텍스-7 HT 디바이스는 새로운 CFP2 폼팩터에서 100 Gbps 저전력 광학 모듈로 전환하기 위해 공간, 전력, 비용 문제 등을 해결해야 하는 디자이너들이 시스템 통합 문제를 해결할 수 있도록 해준다”면서 “28 Gbps 트랜시버는 13.1 Gbps 트랜시버와는 독립돼 있다. 고객들은 어떤 13.1 Gbps 트랜시버도 포기할 필요 없이 이용 가능한 모든 28 Gbps 트랜시버를 이용할 수 있다”고 말했다.
버텍스-7 H580T FPGA는 3개의 이종 3D 디바이스이다. 자일링스는 이를 28 nm 제품군에 배치할 예정이다. 버텍스-7 H870T는 2개의 8-채널 트랜시버 다이와 3개의 FPGA 로직 다이를 단일 디바이스 상에 구성하고 있으며, 이는 하나의 칩에 총 16개의 28 Gbps 트랜시버와 72개의 13.1 Gbps 트랜시버, 876,160개의 로직 셀이 구현되는 것이다.
우 디렉터는 “자일링스의 3D SSI 기술은 자일링스가 한발 앞서 기술을 선도할 수 있도록 해주었으며, 집적도 및 시스템 성능, 전력 소모, BOM 비용 절감 및 생산성 측면에서 최고 수준을 달성한 올 프로그래머블(All Programmable) 디바이스를 공급할 수 있게 했다”고 말했다. 그는 또 “버텍스-7 2000T 디바이스에서 68억 개의 트랜지스터와 1,954,560 로직 셀을 갖춘 디바이스를 만들기 위해 4개의 로직 슬라이스를 실리콘 인터포저 상에 나란히 적층하는 3D SSI 기술을 사용했으며, 이는 경쟁사의 가장 큰 용량의 28 nm FPGA에 비해 두 배에 달하며, 무어의 법칙에서 제시된 트랜지스터 수보다 두 배를 넘어서게 될 것이다. 이제 버텍스-7 HT 디바이스에서 우리는 단일 칩에 28 Gbps 트랜시버 슬라이스와 함께 28 nm FPGA 슬라이스를 모두 실리콘 인터포저에 적층하기 위해 3D SSI 기술을 활용했다”고 언급했다.
SSI 기술에 대해, 우 디렉터는 “자일링스 고객들이 차별화된 가치를 100 Gbps 광통신 장비 분야의 고객들에게 제공하고, 유선통신 산업에서 차세대 400G 장비의 개발을 가속화할 수 있도록 했다”고 덧붙였다.
끝없는 대역폭 요구
자일링스의 버텍스-7 FPGA 제품 라인 매니저인 알렉스 골드하머(Alex Goldhammer) 씨는 점점 더 많은 시스템이 인터넷 및 사설 네트워크 망에 연결되고, 더 큰 파일을 전송하기 위해 보다 높은 대역폭이 요구되고 있으며, 전 세계에 걸쳐 고품질의 비디오 및 오디오 스트리밍이 증가하고 있다는 점을 지적했다. 이러한 요구에 부응하기 위해 서비스 공급업체들은 비트당 더 낮은 비용으로 보다 높은 대역폭의 유선통신 장비를 원하고 있다. 특히 유선통신 분야는 최근 형성되고 있는 100 Gbps 광통신 트랜시버 표준(가장 주목받은 CFP2 광통신 및 OIF CEI-28-VSR, IEEE 802.3ba)에 부합하는 장비를 구현하고 있다.
100 Gbps 인프라 확장의 핵심은 OTN(Optical Transport Network) 트랜스폰더 및 먹스폰더와 100G 이더넷 카드이다. 네트워크 회사는 데이터가 광통신 케이블을 통해 전 세계를 횡단하기 때문에 데이터의 무결성 및 적절한 라우팅을 유지하기 위해 이러한 OTN 카드를 광통신 네트워크(초고속 분야)의 센터 및 코어에 배치한다.
골드하머 매니저는 기업들은 현재 1세대 100 Gbps OTN 트랜스폰더 카드를 갖추고 있으며, 보통 이것은 각각 하나 혹은 2개의 ASSP나 하나의 FPGA 시리즈로 구성되어 있다고 언급했다. 이러한 1세대 100 Gbps OTN 카드는 CFP(C Form-factor Plug gable) 광학 모듈을 통해 광통신 케이블에서 입력을 송수신한다. 그런 다음 ASSP는 CFP에서 10x11.1G OTL 4.10 및 CAUI(100 Gbps 보조 장치 인터페이스)를 이용하고, 데이터를 CAUI를 통해 FPGA로 전송하기 전에 100 Gbps GFEC(Gbps Forward Error Correction)와 OUT-4 프레이밍 및 100GE 매핑을 수행한다. FPGA는 보통 백플레인이 데이터를 네트워크상의 다음 지점, 즉 궁극적인 도착점으로 라우팅시키는 데 필요한 형태로 프로토콜을 변환하기 위해 사용된다.
골드하머 매니저는, 상대적으로 부피가 크고 고가인 CFP 광학 모듈은 이러한 1세대 100Gbps OTN 전송 카드의 주요 장애요소라고 지적했다. 최근 업계에서는 이 문제를 해결하기 위해 동일한 전력 엔벨로프에서 CFP보다 높이는 약간 작고 폭(피치)은 절반으로 줄인 100 Gbps 라인 카드를 위한 광학 모듈인 CFP2 폼팩터를 만들었다. CFP2의 출현으로 장비업체들은 기존 CFP-기반 라인 카드를 유닛 면적당 2개의 CFP2 채널을 가진 새로운 라인 카드로 교체할 수 있게 됐으며, 각 카드 슬롯의 대역폭을 두 배로 늘리고 데이터 센터의 대역폭 또한 잠재적으로 두 배까지 증가시킬 수 있다(그림 2 참조).
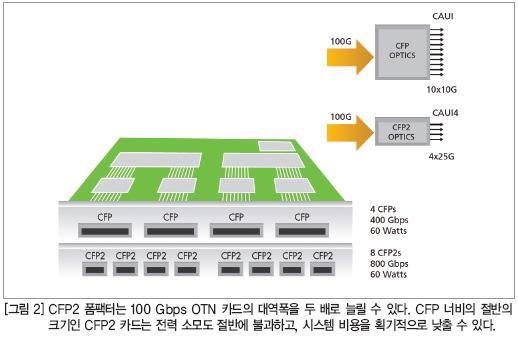
하지만 골드하머 매니저는 CFP2는 새로운 기술적 문제를 수반한다고 지적했다. 그는 “CFP2는 25 Gbps에서 28 Gbps의 트랜시버와 IBIS-AMI 모델을 이용한 PCB 채널 모델링, 그리고 고속 시리얼 모델링 소프트웨어 툴을 필요로 한다. 각 카드는 대체되는 CFP 카드와 동일한 전력 한계치를 유지해야 한다”고 설명했다. 또한 “CFP에서 CFP2로 전환하면 와트당 두 배의 대역폭을 달성할 수 있지만, 이 대역폭을 처리하기 위해서 각 카드 상의 칩 용량이 두 배가 되고, 특히 전력 한계치도 두 배가 된다면 이는 성공적이라 할 수 없다”고 지적하고 “CFP2는 집적도가 매우 뛰어난 보다 정교한 실리콘 디바이스가 필요하다”고 덧붙였다.
장비 제조업체들이 CFP2 카드를 위해 현재 고려하고 있는 아키텍처는 5개의 디바이스로 구성되어 있다. 골드하머 매니저는 이는 4개의 ASSP와 하나의 FPGA라고 설명했다. 각 카드는 2개의 CFP2 광학 모듈을 갖게 되며, 기어박스 ASSP와의 인터페이스를 위해 4x27G OTL 4.4를 사용한다. 기어박스는 4x27G OTL 4.4 신호를 10x11.1G OTL 4.10으로 차례로 디멀티플렉싱한다. 그런 다음 다른 ASSP가 100 Gbps GFEC, OTU-4 프레이밍, 100GE 매핑을 수행하고 CAUI 인터페이스 상에서 데이터를 FPGA로 전송한다. 다음에는 각 CFP2의 2개의 채널을 통해 데이터를 보드상의 FPGA로 전송하며, 네트워크상의 다음 지점, 즉 궁극적인 도착지점으로 데이터를 차례로 보내기 위해 백플레인을 위한 CAUI-투-인터라켄 브리지처럼 동작한다(그림 3).
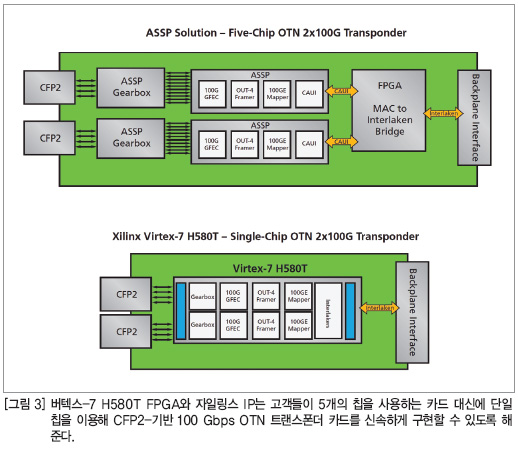
골드하머 매니저는 “이러한 설정은 보통 4개의 ASSP와 하나의 FPGA가 필요하게 된다. 이러한 설정의 가장 큰 문제는 전력, 복잡성, 비용이다. ASSP가 두 배가 되면 전력 한계치도 당연히 늘어날 것이다”고 말했다.
CFP2 카드가 CFP 대역폭의 두 배를 달성하는 반면, CFP2 모듈(2개의 100 Gbps CFP2 포트를 갖춘)은 전체 카드에 할당된 동일한 전력 한계치를 넘지 않도록 단일-포트 CFP 모듈에 할당된 전력 한계치를 유지해야 한다. 골드하머 매니저는 이러한 장비의 운영 비용은 다수의 시스템을 설치해야 하고 엄격한 전력 용량을 유지해야 하는 통신사들에게 상당한 부담이 된다고 설명했다. 그는 “통신사들은 전력 한계치는 유지하면서도 두 배의 향상된 대역폭을 원하기 때문에, 이러한 부담의 상당부분이 반도체 공급업체들에게 부과되며, 더불어 더 낮은 전력소모도 실현해야 한다”고 말했다.
골드하머 매니저는 새로운 버텍스-7 H580T FPGA와 자일링스 IP를 통해 100 Gbps OTN 라인 카드 제조업체들은 5개의 칩을 모두 이용하는 대신 하나의 버텍스-7 H580T만을 사용해 CFP2-기반 OTN 카드의 가치를 보다 극대화할 수 있다고 말했다. 그는 “버텍스-7 H580T FPGA는 CFP2 100Gbps OTN 트랜스폰더 카드 시장의 요건에 시의 적절하고 완벽하게 부합하는 혁신적인 디바이스이다”고 밝혔다.
버텍스-7 H580T FPGA와 자일링스 IP를 통해 기업들은 카드 상에 2개의 CFP2 채널이 있는 CFP2-기반 카드용 아키텍처를 하나의 버텍스-7 H580T FPGA로 구현할 수 있다. 이 FPGA는 기어박스와 10 Gbps GFEC, OTU-4 프레이밍, 100GE 매핑, 인터라켄 브리징을 하나의 디바이스에 통합하고 있다(그림 3 참조).
골드하머 매니저는 “이는 다중-칩 ASSP 및 ASIC 구성보다 전력 소모는 훨씬 낮고, 보다 빠르고 안정적이며, 또한 생산 비용을 더욱 절감할 수 있는 단일 칩 솔루션”이라며, “여러 칩을 사용할 필요가 없고 이와 관련된 전력 및 쿨링 회로를 제거할 수 있다. 자일링스는 버텍스-7 H580T FPGA를 통해 CFP2-기반 OTN 전송 카드를 위한 엄청난 전력 용량을 사용할 필요 없이 집적도, BOM 비용 절감, 향상된 시스템 성능 측면에서 보다 많은 가치를 고객에게 제공하고 있다”고 말했다.
이와 더불어 자일링스는 통신장비 업체들이 디자인 생산성을 가속화하고 단일 칩 100G 광-기반 카드를 보다 빨리 마켓에 출시할 수 있도록 적절한 IP를 갖추고 있다. 내부에서 개발하거나 전략적 합병을 통해 자일링스는 100 Gbps 기어박스, Ethernet MAC, OTN, 인터라켄 IP로 구성된 완벽한 패키지를 제공하고 있다. 골드하머 매니저는 “자일링스는 28 nm 버텍스-7 FPGA의 로직 셀 슬라이스에 디자인할 수 있도록 디바이스 상에서 이러한 모든 코어를 최적화했다. 자일링스는 누설전류를 획기적으로 줄여주고 고성능 및 전력소모 간의 최적의 조합을 이룬 TSMC의 28 nm HPL(High Performance Low-Power) 기술을 이용해 이 슬라이스를 만들었다”고 설명했다.
SSI 기술 및 28 Gbps 트랜시버
오늘날 고속 통신장비의 가장 큰 도전과제 중 하나는 양호한 신호 무결성을 유지하기 위해 트랜시버의 적절한 기능을 보장하는 것이다. 골드하머 매니저는 “트랜시버는 아날로그 회로이기 때문에, 특히 노이즈를 비롯한 수많은 요인들로부터 영향을 받을 수 있다. 대부분의 혼성신호(mixed-signal) 디바이스에서 트랜시버는 보통 디바이스 중앙의 디지털 회로로부터 이를 차폐시키기 위해 디바이스 가장자리에 차폐시켜 배치한다. 디지털 회로는 노이즈에 쉽게 영향을 받기 때문에 일반적으로 이를 아날로그로부터 분리시키는 것이다”라고 설명했다.
지난 10년에 걸쳐 초당 기가비트 단위로 대역폭을 증가시키기 위해 업계는 고속으로 이동하는 신호를 빠르게 송수신할 수 있도록 고속 아날로그 트랜시버에 의존해왔다. 전통적으로 가장 우선시 되는 것은 트랜시버의 더 높은 대역폭이었고, 그만큼 더욱 견고한 신호 무결성을 유지하는 것이다.
골드하머 매니저에 따르면, 버텍스-7 H580T FPGA는 보다 높은 집적도의 원칩 SSI 기술 솔루션이기 때문에 CFP2-기반 라인 카드를 구현할 경우 보다 향상된 성능을 달성할 수 있다. 그는 “4x25G 인터페이스로 전환하면, 10x10G 인터페이스 라우팅의 복잡성을 획기적으로 낮출 수 있다. 비록 25G~28G 트랜시버에 대한 몇몇 우려가 있긴 하지만 자일링스의 SSI 기술을 통해 자일링스는 이러한 복잡성을 상당히 절감시킬 수 있다”면서 “민감한 아날로그 회로인 28G 트랜시버는 물리적으로 디지털 로직과 분리되어 있다. 이러한 아키텍처는 디지털 트랜시버가 풍부한 다이를 효과적으로 분리시킬 수 있다”고 설명했다.
골드하머 매니저는 “28G 트랜시버는 최상의 성능을 유지할 수 있도록 고속 공정기술로 생산되며, 이에 반해 FPGA 슬라이스는 최저 총 전력 소모를 유지하도록 28 nm HPL 공정으로 생산된다”면서 “그 결과 버텍스-7 H580T FPGA 상의 28 Gbps 트랜시버의 성능 및 신호 무결성은 매우 뛰어나다”고 설명했다.(이러한 트랜시버의 동작 데모는 유튜브 비디오에서 확인가능:
http://www.youtube.com/watch?v=FFZVwSjRC4c&feature=player_profilepage)
골드하머 매니저는 SSI 아키텍처로 제공되는 물리적 분리를 통해 자일링스는 현재 제공되고 있는 경쟁사의 가장 큰 디바이스에 비해 두 배에 달하는 8개의 28 Gbps 트랜시버를 버텍스-7 H580T FPGA에서 구현할 수 있게 되었다고 언급했다.
더욱 중요한 것은 버텍스-7 H580T FPGA는 자일링스가 28 nm 제품군에서 제공하는 디바이스 중 최고의 트랜시버가 아니라는 것이다. 자일링스는 조만간 버텍스-7 H870T 디바이스를 출시할 계획이며, 이 디바이스는 16개의 28 Gbps 트랜시버와 72개의 13.1 Gbps 트랜시버, 876,160개의 로직 셀을 가지고 있다. 골드하머 매니저는 고객들이 H580T 디바이스의 모든 트랜시버 용량을 사용한다면, 초당 총 2.78테라비트의 시리얼 커넥티비티가 가능한 디자인을 구현할 수 있을 것이라고 말했다.
그는 “모놀리식 FPGA 상에 다수의 28 Gbps 트랜시버를 배치하는 것은 비현실적이며, 비용적으로도 감당할 수 없는 일이다. 다행히 SSI 기술을 통해 8개에서 16개의 28 Gbps 트랜시버에 이르는 확장 가능한 FPGA 제품군을 구현할 수 있었다”고 언급했다. ASSP 공급업체 및 다른 FPGA 벤더들은 많아 봐야 4개의 28G 트랜시버를 가지고 있다. 이는 40 및 28 nm 공정에서 모놀리식으로 이러한 작업을 수행하는 것은 상당한 도전과제임을 보여주는 것이다.
버텍스-7 H870T 디바이스는 차세대 400G 유선통신 시장을 겨냥하고 있다. 골드하머 매니저는 “400G 시장은 아직 멀리 있지만, 기업들은 이미 연구소에 이를 검토하기 시작했으며 표준 제품은 아직 얻지 못했다”며 “자일링스가 이를 수행할 수 있는 능력의 디바이스를 갖추고 있다는 것은 정말 놀라운 일이다. 자일링스는 이러한 기업들이 400G 개발을 가속화하고 혁신을 주도할 수 있도록 도와줄 수 있다”고 피력했다.
버텍스-7 H580T 및 H870T FPGA와 함께 자일링스는 28 nm 제품군의 하나로 버텍스-7 H290T 디바이스도 발표할 계획이다. 자일링스의 3D SSI 기술을 활용함으로써 H290T는 24개의 13.1 Gbps 트랜시버와 8개의 28 Gbps 트랜시버, 284,000개의 로직 셀을 제공하게 된다. 골드하머 매니저는 버텍스-7 H290T는 특히 2x100G 기어박스 시장에 잘 부합한다고 덧붙였다.
버텍스-7 H580T FPGA의 첫 번째 실리콘은 주요 고객들에게 현재 선적되고 있으며, 최근 발표된 비바도(Vivado™) 디자인 수트를 통해 개발 툴이 지원된다.
|
리니어 테크놀로지, 저잡음 완전 차동형 버퍼 |
<저작권자(c)스마트앤컴퍼니. 무단전재-재배포금지>




 리니어 테크놀로지는 출력 리퍼 잡음이 1.5 nV/√Hz에 불과한 완전 차동형 버퍼 앰프(제품명: LTC6417)를 출시한다고 밝혔다. LTC6417은 차동 50 Ohm 부하를 구동시키며 14 및 16비트 파이프라인 ADC를 구동하는데 최적화됐다. 이 제품은 입력 단자에서 DC 혹은 AC로 커플될 수 있으며, 최고 600 MHz 이상의 신호에서 뛰어난 왜곡 성능을 달성한다. 140 MHz 일때 OIP3은 46 dBm, HD3이 -69 dBc이며, 2.4 VP-P출력 스윙으로 50 Ohm 부하를 제공한다. LTC6417은 ADC와 인터페이스를 단순화할 수 있도록 설계된 다양한 기능을 제공한다. LTC6417은 단일 이득 버퍼로써 구성할 수 있다. 입력 임피던스는 18.5 kOhm이기 때문에, 추가적인 이득은 입력 단자에서 1:4 또는 1:8 트랜스포머를 적용함으로써 달성될 수 있다. 낮은 임피던스 출력은 파이프라인 ADC에 용량성 충전 인젝션 커먼(capacitive charge injection common) 관리를 지원한다. 고속 출력 클램프는 단일 핀으로 프로그램 될 수 있기 때문에ADC 오버레인지(overrange) 상황을 방지한다. 클램프가 출력 전압을 제한시킬 때 오버레인지 핀은 신호를 보낸다. 출력 커먼 모드 핀은 LTC6417 출력 스윙과 ADC의 입력 범위와 쉽게 매치시켜 준다.
리니어 테크놀로지는 출력 리퍼 잡음이 1.5 nV/√Hz에 불과한 완전 차동형 버퍼 앰프(제품명: LTC6417)를 출시한다고 밝혔다. LTC6417은 차동 50 Ohm 부하를 구동시키며 14 및 16비트 파이프라인 ADC를 구동하는데 최적화됐다. 이 제품은 입력 단자에서 DC 혹은 AC로 커플될 수 있으며, 최고 600 MHz 이상의 신호에서 뛰어난 왜곡 성능을 달성한다. 140 MHz 일때 OIP3은 46 dBm, HD3이 -69 dBc이며, 2.4 VP-P출력 스윙으로 50 Ohm 부하를 제공한다. LTC6417은 ADC와 인터페이스를 단순화할 수 있도록 설계된 다양한 기능을 제공한다. LTC6417은 단일 이득 버퍼로써 구성할 수 있다. 입력 임피던스는 18.5 kOhm이기 때문에, 추가적인 이득은 입력 단자에서 1:4 또는 1:8 트랜스포머를 적용함으로써 달성될 수 있다. 낮은 임피던스 출력은 파이프라인 ADC에 용량성 충전 인젝션 커먼(capacitive charge injection common) 관리를 지원한다. 고속 출력 클램프는 단일 핀으로 프로그램 될 수 있기 때문에ADC 오버레인지(overrange) 상황을 방지한다. 클램프가 출력 전압을 제한시킬 때 오버레인지 핀은 신호를 보낸다. 출력 커먼 모드 핀은 LTC6417 출력 스윙과 ADC의 입력 범위와 쉽게 매치시켜 준다.