- 2023-06-08
글/ 데니 왕(Denny Wang) AE, 샐리 쳉(Sally Tseng) AE, 아나로그디바이스(Analog Devices, Inc.)
이 글에서는 MCU와 ADC 사이에 고속 SPI(serial peripheral interface) 데이터 처리 드라이버 설계에 대해 설명한다. 먼저 SPI 드라이버를 최적화하는 방법과 ADC와 MCU에 요구되는 구성에 대해서 설명한다. 그 다음에는 SPI와 DMA(direct memory access) 데이터 처리를 위한 코드 예제에 대해서 설명한다. 끝으로, 서로 다른 MCU(ADuCM4050, MAX32660)에 동일한 드라이버를 사용해서 얼마만큼의 ADC 쓰루풋을 달성할 수 있는지 설명한다.
.jpg)
기술의 진보와 함께, 저전력 사물인터넷(IoT) 및 에지/클라우드 컴퓨팅에서 보다 정밀한 데이터 전송이 필요해졌다. 그림 1의 무선 센싱 시스템은 24비트 아날로그-디지털 컨버터(ADC)를 채택한 고정밀 데이터 수집 시스템이다. 이 경우에 문제는, 마이크로컨트롤러 유닛(MCU)이 데이터 컨버터의 직렬 고속 인터페이스를 감당할 수 있느냐 하는 것이다.
범용 SPI 드라이버
MCU 회사들은 각 MCU에 대한 예제 코드에서 범용 SPI 드라이버/API를 제공한다. 일반적으로 범용 SPI 드라이버/API는 여러 구성들을 담고 있거나 진술들을 정의하고 있는 대다수 사용자들의 애플리케이션을 지원할 수 있다. 이처럼 범용 드라이버는 너무 많은 구성들을 지원하도록 구현되다 보니, 예컨대 ADC 데이터 수집 같은 특수한 경우에는 범용 SPI 드라이버가 ADC 데이터의 고속 쓰루풋을 만족시키지 못할 수도 있다. 해당 애플리케이션에 사용되지 않는 구성들은 오버헤드를 가중시키고 시간 지연을 유발할 것이다.
기본 구상
SPI를 통해서 ADC 출력 데이터를 인출하기 위해, 전력 소모가 적고 고속 성능이 가능한 MCU를 메인 디바이스로서 선택했다. 그런데 데이터 처리가 ADI SPI 드라이버를 기반으로 할 때, ADC 애플리케이션에 사용되지 않는 명령들 때문에 속도가 떨어질 수 있다.
이 글에서는 ADuCM4050과 AD7768-1을 사용하는 것을 예로 들어서 어떻게 하면 ADC로부터 가능한 최대의 속도를 끌어낼 수 있는지 설명한다. 256kHz의 최대 출력 데이터 전송속도에도 불구하고(디폴트 필터 사용), ADuCM4050은 현재로서는 8kHz로 제한된다. 출력 레이트를 가속화하기 위해 활용 가능한 솔루션은 불필요한 명령들을 제거하는 것과 DMA 컨트롤러를 사용하는 것이다. 이러한 구상들은 아래에서 설명한다.
MCU가 메인
ADuCM4050 MCU는 초저전력 마이크로컨트롤러 시스템으로서, 26MHz 메인 클럭 속도로 동작한다. 이 시스템은 Arm® Cortex®-M4F 프로세서를 채택하고 있다. ADuCM4050은 3개의 SPI를 제공하는데, 각 SPI는 2개의 DMA 채널(수신과 송신)을 포함하고 이 채널들은 DMA 컨트롤러와 인터페이스한다. DMA 컨트롤러와 DMA 채널들은 메모리와 주변장치 간에 데이터 전송을 위한 수단을 제공한다. 이는 데이터를 전달하기 위한 효율적인 방법으로서, 코어의 부담을 덜어 코어가 다른 작업을 처리할 수 있도록 한다.
ADC가 노드
AD7768-1은 24비트 저전력 고성능 시그마-델타(Σ-Δ) ADC이다. 출력 데이터 레이트(ODR)와 전력 소모 모드를 사용자의 필요에 따라서 조절할 수 있다. 표 1에서 보듯이, 데시메이션 비와 전력 모드에 따라서 ODR이 결정된다.
.jpg)
AD7768-1의 또 다른 중요한 특징은 연속 읽기 모드이다. ADC의 출력 데이터는 레지스터 0x6C에 저장된다. 일반적으로 ADC 레지스터에 있는 데이터는 각각의 읽기/쓰기 동작 전에 주소값 지정을 필요로 한다. 연속 읽기 모드는 매 데이터 준비 신호 후에 0x6C 레지스터로부터 데이터를 직접 인출할 수 있다. ADC 출력 데이터는 24비트 디지털 신호이며, 표 2에서 보듯이 볼트(V)로 변환한다.
데이터 플로우 연결 다이어그램
ADuCM4050과 AD7768-1 사이의 데이터 처리를 살펴보자. 그림 4는 핀 연결을 보여준다.
MCU GPIO28에서 ADC RST_1 핀으로 리셋 신호를 전송하고, ADC DRDY_1에서 MCU GPIO27로 데이터 준비 신호를 전송한다. 나머지 핀들의 연결은 일반적인 SPI 구성과 마찬가지다. 여기서는 MCU가 메인이고 ADC가 노드이다. SDI_1은 MCU로부터 ADC 레지스터 읽기/쓰기 명령을 수신하고, DOUT_1은 MCU로 출력 데이터를 전송한다.
데이터 처리 구현
인터럽트 데이터 처리
연속적 데이터 처리를 구현하기 위해서 GPIO27(DRDY로 연결)을 인터럽트 트리거로 사용했다. ADC가 GPIO27로 데이터 준비 신호를 전송하면, MCU가 콜백 함수를 실행한다. 이 함수에 데이터 처리 명령들이 들어 있다. 그림 5에서 보듯이, 인터럽트 A와 인터럽트 B 사이의 간격에 데이터 수집이 이뤄져야 한다.
ADI SPI 드라이버를 사용해서 ADC와 MCU 사이의 데이터 처리를 손쉽게 구현할 수 있다. 하지만 이 드라이버에서는 중복된 명령들 때문에 ADC ODR이 8kHz로 제한된다. 이 프로세스를 가속화하기 위해서는 코드를 최대한 간결하게 최적화해야 한다. DMA 데이터 처리를 위해서는 두 가지 기법을 사용할 수 있다. 기본 모드 DMA 처리와 핑퐁 모드 DMA 처리가 그것이다.
기본 모드 DMA 처리
DMA 처리를 위해서는 그 전에 먼저 몇 가지 SPI 및 DMA 설정이 필요하다(그림 6의 예제 코드 참조). SPI_CTL은 SPI 구성이다. ADI SPI 드라이버에 설정된 값으로부터 SPI_CTL=0x280f를 도출할 수 있다. SPI_CNT는 전송 바이트 수이다. 매 DMA 처리에 16의 고정된 비트 수만 전송할 수 있으므로, SPI_CNT는 2의 배수여야 한다.
이 글에서 설명하는 사례의 경우에는 ADC의 24비트 출력 데이터를 지원하기 위해 SPI_CNT=4를 선택했다. SPI_DMA 레지스터는 SPI DMA 활성화다. SPI_DMA=0x5는 수신 DMA 요청을 활성화한다. pADI_DMA0 → EN_SET=(1<<5)는 다섯 번째 DMA 채널(SPI0 RX)의 DMA를 활성화한다.
각 DMA 채널은 표 3에서와 같은 DMA 구조 레지스터를 가진다. 여기서 유의할 점은, Rx FIFO가 레지스터로부터 데이터를 자동으로 밀어내기 때문에 전체 동작에 걸쳐서 소스 주소 값(즉 SPI0 Rx) 끝점은 증분이 필요 없다는 것이다. 이와 달리, 대상 주소값 끝점은 ADI SPI 드라이버에 따라서 함수에 의해서 계산된다(대상 주소값 + SPI_CNT-2). 여기서 현재의 주소값은 내부 배열 버퍼의 주소값이다. DMA 제어 데이터 구성은 소스 데이터 크기, 소스 주소값 증분, 대상 주소값 증분, 남은 전송 횟수, DMA 제어 모드 같은 설정들을 포함한다. 이 값이 0x4D000011이면 표 4에서와 같이 설정된다.
.jpg)
더미 읽기 명령 SPI_SPI0 → RX 후에, SCLK 발진이 시작되고 MISO 라인을 통해서 ADC에서 MCU로 출력 데이터가 전송된다. MOSI 라인으로도 약간의 데이터 전송이 이루어진다. Rx FIFO가 가득 차면 DMA 요청이 생성되고 DMA 컨트롤러를 작동시켜서 DMA 소스(SPI0 Rx FIFO)에서 DMA 대상(내부 배열 버퍼)으로 데이터 전송이 이루어진다. SPI_DMA=0x3에는 Tc 요청이 생성된다.
끝으로, 현재 대상 주소값에 4를 더해서 다음 4바이트 전송에 대해서 대상 주소값을 유지한다.
또 한 가지 유의할 점으로서, 첫 번째 인터럽트가 일어나기에 앞서 메인 함수에 SPI0 DMA 채널에 대해서 pADI_DMA0 → DSTADDR_CLR과 pADI_DMA0 → RMSK_CLR을 둘 다 설정해야 한다. 전자의 레지스터는 ‘DMA 채널 대상 주소 감소 활성화 지우기’로서, 증분 모드에서 매 DMA 전송 후 대상 주소값 이동을 설정한다(대상 주소값 계산 함수는 증분 모드에서만 작동한다). 후자의 레지스터는 ‘DMA 채널 요청 마스크 지우기’로서, 채널에 대한 DMA 요청 상태를 해제한다.
그림 7a는 기본 모드 DMA 처리의 시간 다이어그램을 보여준다. 시간 슬롯들은 각각 DRDY 신호, SPI/DMA 설정, DMA 데이터 처리를 나타낸다. 코어가 쉬는 시간을 더 잘 활용하기 위해, DMA 컨트롤러가 데이터 전송을 하는 동안 이 코어에 또 다른 작업들을 할당하는 방법을 생각해 볼 수 있다.
핑퐁 모드 DMA 처리
더미 읽기 명령이 수행되고 나면, DMA 컨트롤러가 데이터 처리를 시작하고, MCU의 코어는 아무 일도 하지 않고 쉬고 있다. 만약 코어와 DMA 컨트롤러가 동시에 일을 하게 할 수 있다면 작업을 더 이상 직렬이 아니라 병렬로 처리할 수 있다. 그러면 (코어가 하는) DMA 구성과 (DMA 컨트롤러가 하는) DMA 데이터 처리를 동시에 처리할 수 있는 것이다.
이러한 구상을 실현하기 위해서는 DMA 컨트롤러에 핑퐁 모드(ping-pong mode)라고 하는 것이 필요하다. 핑퐁 모드는 기본 DMA 구조와 교대 DMA 구조라고 하는 두 세트의 DMA 구조를 사용한다. DMA 컨트롤러는 매 DMA 요청마다 이 두 구조 사이에서 자동으로 전환한다. 처음에 0으로 설정된 변수 p가 기본 DMA 구조(p = 0) 또는 교대 DMA 구조(p = 1)에 작업을 담당하게 할지를 정한다.
만약 p = 0이면, 더미 읽기 명령에 DMA 일차 데이터 처리가 시작된다. 이와 동시에 교대 DMA 구조에 값을 지정하여 다음 인터럽트 사이클에 작업을 맡게 한다. 만약 p = 1이면, 기본 구조와 교대 구조의 역할이 바뀐다. DMA 처리 동안에 DMA 구조를 변경하는 것은 할 수 없으며, 단지 기본 DMA 모드에서 일차 구조만 작동하도록 한다.
핑퐁 모드를 사용하면 DMA 컨트롤러가 기본 DMA 구조를 읽는 동안 코어가 교대 DMA 구조에 접근하고 쓰기 작업을 할 수 있다(혹은 그 반대). 그림 7b에서 보듯이, 지난 번 사이클에서 DMA 구조 구성이 완료되었기 때문에 ADC에서 MCU로 DRDY 신호가 전송된 후에 바로 DMA 데이터 처리를 할 수 있다. 그러므로 코어와 DMA는 서로 상대방이 일을 마치기를 기다릴 필요 없이 동시에 작업을 할 수 있다. 이로써 총 동작 시간을 크게 단축할 수 있으므로 ADC ODR을 향상시킬 수 있는 여지가 생겨난다.
.jpg)
인터럽트 핸들러 최적화
데이터 준비 신호 사이의 시간 간격은 콜백 함수 명령들을 실행하는 시간뿐만 아니라 ADI GPIO 인터럽트 핸들러 명령들을 실행하는 시간도 포함한다.
MCU를 작동시키면 코어가 스타트업 파일(startup.s)을 실행한다. 이 파일은 모든 이벤트 핸들러를 정의하고 있으며, 여기에는 GPIO 인터럽트 핸들러도 포함된다. GPIO 인터럽트가 트리거되면 인터럽트 핸들러 함수(ADI GPIO 드라이버에 들어 있는 GPIO_A_INT_HANDLER와 GPIO_B_INT_HANDLER)가 실행된다. 일반적인 인터럽트 핸들러 함수는 코어가 모든 GPIO 핀들을 탐색해서 트리거된 핀을 찾아내고, 이의 인터럽트 상태를 해제하고, 등록된 콜백 함수를 실행한다.
이 글에서 설명하는 ADC 애플리케이션에서는 DRDY가 유일한 인터럽트 신호이다. 그러므로 이 함수를 최적화해서 프로세스 속도를 높일 수 있다. 이를 위해 가능한 솔루션은 (1) 스타트업 파일로 리타겟팅(retargeting) 하거나 (2) 원래의 인터럽트 핸들러를 수정하는 것이다. 여기서 말하는 리타겟팅은 인터럽트 핸들러를 자체 정의해서, 이를 스타트업 파일에 들어 있던 원래 인터럽트 핸들러와 교체하는 것이다.
한편, 수정을 위해서는 자체 정의된 GPIO 드라이버가 필요하다. 여기서는 후자의 방법을 사용해서 함수를 그림 8에서와 같이 수정한다. 이 함수는 DRDY에 연결된 핀의 인터럽트 상태를 해제하고 곧바로 콜백 함수로 넘어간다. 유의할 점은, “include in build target” 박스에 표시한 체크를 해제해서 원래 GPIO 드라이버를 차단해야 한다는 것이다.
결과
속도 성능
사용자가 200개의 24비트 ADC 출력 데이터를 읽는다고 가정해 보자. SPI 비트 레이트는 13MHz로 설정되었다. 측정을 위해서 DRDY 신호와 SCLK를 오실로스코프로 연결한다. DRDY 신호와 SPI 데이터 처리(DMA 처리) 시작 사이의 시간 간격을 측정함으로써 이 글에서 설명한 각각의 방법으로 속도 향상을 수치화할 수 있다. 편의상, DRDY 신호부터 SCLK 신호 시작까지의 시간 간격을 Δt라고 하겠다. 13MHz SPI 비트 레이트의 경우, Δt는 다음과 같이 측정되었다:
- (a) 기본 모드 DMA, Δt = 3.754μs
- (b) 핑퐁 모드 DMA, Δt = 2.8433μs
- (c) 핑퐁 모드 DMA에 인터럽트 핸들러 최적화를 더했을 때 Δt = 1.69μs
(a) 기법과 (b) 기법은 64kHz의 ODR이 가능한데, (c) 기법은 128kHz의 ODR이 가능하다. 이는 (c) 기법이 Δt가 가장 짧고, 그러므로 SCLK가 더 일찍 끝날 수 있기 때문이다. 만약 SCLK 신호, 다시 말해 데이터 처리가 T/2(T는 현재 ADC 출력 데이터 구간) 전에 이루어질 수 있다면, ODR을 배로 높이는 것이 가능하다. 이는 ADI SPI 드라이버의 8kHz ODR 속도 성능과 비교할 때 엄청난 진전이라고 할 수 있다.
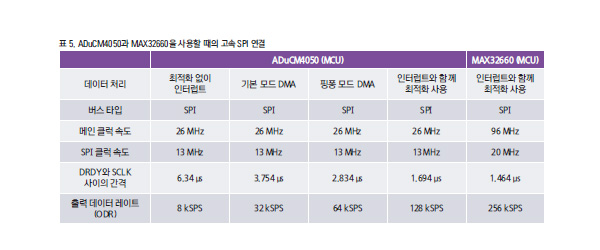
AD7768-1과 MAX32660을 함께 사용했을 때
MAX32660을 사용하면 결과가 어떻게 될까? MAX32660은 메인 클럭 속도가 96MHz인 MCU이다. 이 결과를 확인하기 위해, 인터럽트 데이터 처리와 함께 인터럽트 핸들러 최적화를 사용했다. 이 인터럽트 설정으로 DMA 기능을 사용하지 않고서 256kHz 출력 데이터 레이트를 달성할 수 있다. 그림 10 참조.
.jpg)
맺음말
이 글에서는 선택한 ADC(AD7768-1)와 MCU(ADuCM4050 또는 MAX32660) 사이에 SPI를 통한 고속 데이터 처리를 구현하는 것을 설명했다. 목표로 하는 속도 최적화를 달성하기 위해서 ADI SPI 드라이버에 따라서 데이터 처리를 하되 중복적인 명령들을 삭제했다.
또한 DMA 컨트롤러를 사용해서 코어의 부담을 덜고 연속적 데이터 처리 속도를 높이도록 했다. DMA 핑퐁 모드를 사용하면, 적절한 스케쥴링을 통해서 DMA 구성 시간을 절약할 수 있다. DMA를 통한 가속화와 함께, 인터럽트하려는 핀을 직접 지정하는 방법으로 인터럽트 핸들러를 최적화할 수 있다. 그럼으로써 13MHz SPI 비트 레이트로 128kSPS ADC ODR의 우수한 성능을 달성할 수 있다.
감사의 말씀
이 글을 작성하는데 많은 분들이 큰 도움을 주셨다. 축적된 전문성을 바탕으로 하드웨어, 소프트웨어 지원, 디버깅에 있어서 귀중한 조언을 해주신 찰스 리(Charles Lee)에게 감사드린다. 멘토로서 기술적 지원과 지도를 해주신 윌리엄 첸(William Chen)과, 연륜에서 나온 기술적 경험을 공유해주신 프랭크 창(Frank Chang)에게도 감사드린다.
저자 소개
데니 왕(Denny Wang)은 아나로그디바이스 타이완(Analog Devices Taiwan)에서 1년 반 동안 NCG 프로그램을 이수한 애플리케이션 엔지니어이다. 북경 대학에서 IC 공학으로 석사학위를 취득했다. 대학원에서 반도체 공정, BLDC/PMSM 모터 제어, 아날로그 스키매틱 이전과 관련한 연구 활동을 했다. 2021년에 ADI에 입사했으며, 현재는 시스템 솔루션, 데이터 보안 및 인증, MQTT 무선 전송 지원 업무를 맡고 있다.
샐리 쳉(Sally Tseng)은 ADI 타이완에서 애플리케이션 엔지니어 인턴을 하고 있다. 현재 국립 타이완 대학(NTU)의 졸업 학년으로서 전기공학 전공이다. NTU에서 하는 프로젝트는 주로 아날로그 회로 연구에 관한 것이다. ADI 인턴십 과정 동안 임베디드 시스템과 관련한 업무에 참여하고 있다.
<저작권자(c)스마트앤컴퍼니. 무단전재-재배포금지>