



FPGA 다이나믹 부분 리컨피규레이션 기능으로 상황별 적응 가능하다
비디오-기반 운전자 지원 애플리케이션은 상황에 따라 조정이 가능한 하드웨어를 이용해 효과적으로 실현해 볼 수 있다.
크리스토퍼 클라우스(Christopher Claus) / 독일 뮌헨 기술대학 박사과정
플로리안 알텐라이드(Florian Altenried) / 독일 뮌헨 기술대학 석사과정
월터 스테켈리(Walter Stechele) 독일 뮌헨 기술대학 교수
비디오-기반 운전자 지원 시스템은 다양한 상황에 따라 복잡한 알고리즘을 실시간으로 처리해야 한다. 오토모티브 환경에서 이용 가능한 하드웨어들의 대부분은 순수 소프트웨어 구현에서는 필요한 실시간 프로세싱을 제공하지 않는다. 대신 이러한 시스템은 하드웨어 가속을 요구한다.
ASIC(Application-Specific Integrated Circuits) 혹은 상용 ASSP(Application-Specific Standard Products)와 같은 전용 하드웨어 회로들은 요구되는 실시간 프로세싱 성능을 제공할 수는 있지만, 필요한 유연성 측면에서는 부족하다. 또한 ASIC의 설계시간 및 개발 비용은 지난 여러 해 동안 증가해 왔다. 운전자 지원 시스템의 비디오 알고리즘이 표준화되어 있지 않고, 디자인이 상당히 자주 변경되어야 하기 때문에 ASIC은 적절한 선택이라고 보기 어렵다.
반면 FPGA는 프로그래머블 영역에서 보다 빠른 마켓 출시가 가능하고 비용 절감 및 제품 차별화 기회요소를 제공한다는 점에서 매력적인 대안이 될 수 있다. 하지만 FPGA 디자인에서 얻을 수 있는 로직 기능의 규모는 동일한 프로세스 기술을 이용했을 때 ASIC과는 상당히 다르다.
독일 뮌헨 기술대학의 통합 시스템 연구소는 임베디드 시스템을 위한 MPSoC(Multiprocessor System-on-Chip) 아키텍처를 연구하고 있다. 또 다른 중점 연구 과제는 NoC(Networks-on-chip) 및 메모리 계층을 비롯한 MPSoC 영역을 조사하기 위한 초기 디자인 단계의 하이-레벨 시뮬레이션 방법이다(www.lis.ei.tum.de). 이러한 작업의 일환으로 우리는 실시간 프로세싱이 가능하고 신속하게 다가오는 상황에 대처할 수 있는 비전-기반 운전자 지원 시스템을 위한 리컨피규러블 FPGA-기반 SoC 아키텍처를 개발하는 중이다.
아키텍처 컨셉
우리의 AutoVision 아키텍처는 미래의 비전-기반 운전자 지원 제품을 위해 실시간 리컨피규레이션이 가능한 하드웨어 가속 엔진을 사용한다. AutoVision 시스템에는 오직 디바이스의 한 부분만이 런타임이 이뤄지는 동안 변경된다.
이번 연구의 핵심은 고유의 DPR(Dynamic Partial Reconfiguration) 기능과 자일링스 ISE짋, EDK, 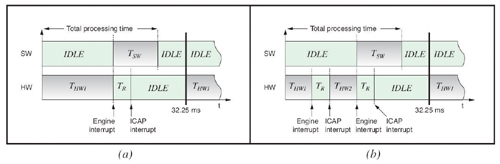 PlanAhead™와 같은 임베디드 디자인 툴을 제공하는 자일링스 FPGA를 사용하는 것이다. 이 아키텍처를 구체적으로 정리하기 전에 우리는 분명히 이러한 접근방식이 광범위한 자일링스의 지원 아래 독립적인 대학 연구가 되기를 원했다.
PlanAhead™와 같은 임베디드 디자인 툴을 제공하는 자일링스 FPGA를 사용하는 것이다. 이 아키텍처를 구체적으로 정리하기 전에 우리는 분명히 이러한 접근방식이 광범위한 자일링스의 지원 아래 독립적인 대학 연구가 되기를 원했다.
동적으로 리컨피규레이션이 가능한 하드웨어는 실시간 제약조건을 실현하기 위해 높은 수준의 유연성과 근본적으로 병렬 특성이 필요한 비디오-기반 운전자 지원 시스템을 위한 최상의 선택이다. 비디오 프로세싱을 위한 알고리즘은 하이-레벨 애플리케이션 코드 및 로우-레벨 픽셀 연산에 그룹화될 수 있다. 하이-레벨 애플리케이션 코드는 상당한 수준의 유연성을 요구하기 때문에 PowerPC짋나 MicroBlaze™와 같은 임베디드 CPU 상에 구현하는 것이 좋은 선택이 될 수 있다. 반면에 픽셀 처리는 병렬로 수많은 픽셀에 동일한 연산을 적용해야 할 필요가 있기 때문에 하드웨어 가속이 좋은 선택이 될 것이다.
다양한 운전조건에 따라 시스템은 비디오 프로세싱을 위한 서로 다른 알고리즘을 사용해야 할 것이다. 이러한 알고리즘의 픽셀-레벨 부분은 시스템 런타임 시에 AutoVision 칩에 로드할 수 있는 다른 하드웨어 가속 엔진을 요구한다. 동시에 우리는 칩 면적을 줄이기 위해 FPGA에서 사용하지 않는 가속기를 제거했다.
DPR은 우리가 이번 연구 프로젝트에 사용한 버텍스-5(Virtex-5)를 비롯해 일부 상용 Virtex짋 제품군에서 제공된다. 특히 DPR은 주간-야간 운전이나 전진-후진, 다른 주행속도(도심 환경 대 고속도로), 다른 기상조건(비, 안개, 눈 등) 등과 같이 상호 배타적인 상황에서 유의미하다.
로직-리소스 과제
리컨피규레이션이 가능한 시스템을 만들기 전에 우리는 먼저 리컨피규러블 인터페이스와 ICAP(Internal Configuration Access Port )를 위한 컨트롤러뿐만 아니라 비트스트림 전송을 위한 고속 인터커넥트를 추가하기 위해 로직 리소스와 관련한 몇 가지 작업을 수행해야만 했다. 이러한 노력은 나중에 DPR 기능의 도움으로 디자인 프로세스 단계에서 상쇄되었다.
ICAP는 컨피규레이션 메모리에 읽기 및 쓰기 액세스가 가능하기 때문에 온칩 셀프-리컨피규레이션에 사용될 수 있다. 이 리컨피규러블 인터페이스는 리컨피규레이션 이전이나 수행하는 동안, 혹은 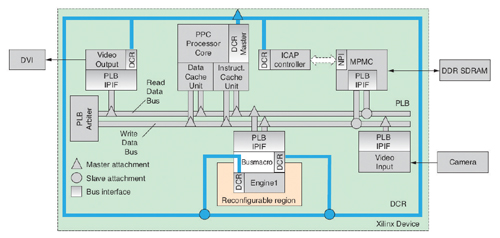 이후에 정적 및 리컨피규러블 부분 간의 안전한 접속을 보장하는 버스 매크로로 구성된다. 현재 우리는 하드와이어드된 매크로를 사용한다. 향후 이러한 매크로는 자일링스의 개발 툴이 언젠가 사용자가 조정할 필요없이 안전한 접속을 보장하게 되면 더 이상 필요없게 될 것이다.
이후에 정적 및 리컨피규러블 부분 간의 안전한 접속을 보장하는 버스 매크로로 구성된다. 현재 우리는 하드와이어드된 매크로를 사용한다. 향후 이러한 매크로는 자일링스의 개발 툴이 언젠가 사용자가 조정할 필요없이 안전한 접속을 보장하게 되면 더 이상 필요없게 될 것이다.
한편 비-리컨피규러블 시스템과 비교해 가능한 적은 리컨피규러블 기능을 사용한 디자인 변경을 하는 것이 중요하다. 만약 ICAP 컨트롤러나 다른 DPR 관련 로직이 디바이스 블록 RAM(20개 혹은 그 이상)의 상당한 수를 차지한다면, 어느 누구도 DPR을 허용하지 않을 것이다. 따라서 온칩 블록 RAM에 저장된 부분적인 비트스트림은 적절한 솔루션이 아니다.
다른 한편으로 리컨피규레이션은 가능한 빨라야 한다. 만약 안전에 민감한 환경에서 비디오-기반 운전자 지원 시스템을 사용하고 있다면, DPR로 인해 비디오 프레임이 드롭되는 것은 허용될 수 없다. 비트스트림 데이터를 고속으로 ICAP 컨트롤러로 전송하기 위해 우리는 ICAP 컨트롤러를 직접 NPI(Native Port Interface)를 통해 MPMC(Multi-Port Memory Controller)와 연결했다. 리컨피규러블 인터페이스로 버스 매크로를 추가하고, 셀프-리컨피규레이션용 ICAP 컨트롤러와 MPMC 상의 별도의 포트를 추가하는 것은 DPR 오버헤드로 간주된다. 리컨피규레이션 규모에 따라, 이들이 수행되어져야 할 때 인터- 혹은 인트라-비디오 프레임(혹은 각각 InterVFR 및 IntraVFR) 리컨피규레이션 중 하나로 프로세스를 나눌 수 있다.
2개의 연속 비디오 프레임 간의 스와핑 리컨피규러블 모듈로서의 InterVFR 절차를 정의했다. (그림 1(a))에 THW1 엔진과 또 다른 엔진인 THW2로 요구되는 이미지 처리 시간을 나타냈다. 스와핑을 위한 리컨피규레이션 시간은 TR로 표현했으며, 블랭크 비트스트림으로 리컨피규러블 영역을 비워두고 두 번째 부분 비트스트림을 사용해 새로운 모듈을 로딩하는 작업까지 포함된다. 만약 THW1+ TR+TSW<32.25ms(초당 31프레임)이면, InterVFR이 가능하고, 이는 엔진의 이미지 프로세싱과 디바이스의 리컨피규레이션이 THW2가 시작되기 전에 수행될 수 있음을 의미한다.
IntraVFR은 이러한 부분을 위해 하나의 비디오 프레임 안에 스와핑 다중 리컨피규러블 모듈을 포함하고 있다. FPGA-기반 광 플로우 계산을 위한 하드웨어 가속기는 이 글의 예제처럼 동작할 수 있다. 이는 순차적으로 실행되는 2개의 엔진으로 구성되며, 파이프라인화 될 수 없다. 첫 번째 엔진으로 이미지를 처리하는 시간은 THW1로 나타냈으며, 두 번째 엔진에서 요구되는 시간은 THW2로 표현했다. 두 엔진의 부분적 비트스트림은 모두 동일한 사이즈로 간주된다. 따라서 두 엔진에 대한 컨피규레이션 시간은 동일하며, (그림 1(b))에 TR(블랭크 및 모듈 비트스트림)로 나타내었다. 만약 THW1+ THW2+2_TR<32.25ms(31 fps)이면, IntraVFR이 가능하다.
최상의 경우는 리컨피규레이션 시간 TR이 CPU 상에서 중간 결과를 처리하는데 사용되는 시간과 겹쳐지는 것이다(그림에서 TSW로 나타냄). (그림 1(a))에서 보여주는 것처럼, TR이 완벽하게 TSW와 겹쳐지기 때문에 InterVFR을 위한 추가 시간이 필요없다. 또한 이는 순차적으로 동작하는 2개의 엔진이 IntraVFR을 사용하여 교체될 때, 두 번째 컨피규레이션에서도 그대로 적용된다. 이 경우 하나의 비디오 프레임을 위한 전체 프로세싱 시간은 한번의 리컨피규레이션 TR을 위한 시간만큼 증가하게 될 것이다.
InterVFR 혹은 IntraVFR 시스템이 구현될 수 있도록 하기 위해서는 디자이너는 미리 여러 단계를 수행해야만 한다.
알고리즘 소프트웨어(SW) 프로토타입을 생성한 후에 우리는 성능 집약적 부분을 정의하기 위해 코드를 프로파일 했다. 이러한 것들은 이후 하드웨어(HW)에서 실행되어야 하기 때문이다. 또한 모듈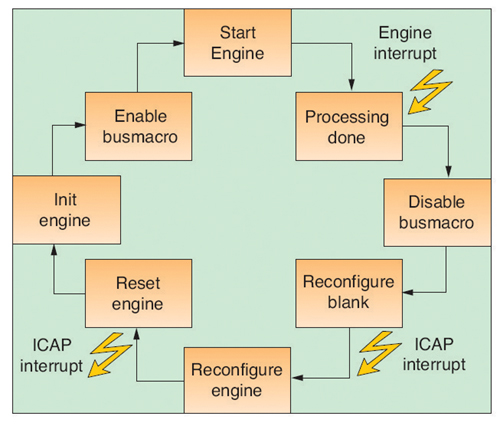 러 및 빌딩-블록-기반 픽셀 프로세싱 체인을 활용하여 픽셀 연산을 위한 하드웨어 가속기를 구현했다. 모듈러 AtuoVision 컨셉이 데이터-입력, 중간-데이터, 데이터-출력 경로를 재사용할 수 있도록 하기 때문에 처음부터 싱글 픽셀 연산과 이 다음 연산만
러 및 빌딩-블록-기반 픽셀 프로세싱 체인을 활용하여 픽셀 연산을 위한 하드웨어 가속기를 구현했다. 모듈러 AtuoVision 컨셉이 데이터-입력, 중간-데이터, 데이터-출력 경로를 재사용할 수 있도록 하기 때문에 처음부터 싱글 픽셀 연산과 이 다음 연산만
<저작권자(c)스마트앤컴퍼니. 무단전재-재배포금지>



