



글 | 트렁 트란(Trung Tran) 알테라 코퍼레이션 제품 마케팅 매니저
타이밍 클로저는 고속 FPGA 설계에서 매우 중요하다. 이 글에서는 타이밍 클로저에 관련된 해결과제에 대해 살펴보고 어떻게 간단한 HDL 변경으로 타이밍 문제를 해결하고 원하는 타이밍 클로저를 달성하는 데 필요한 시간을 단축할 수 있는지 설명한다.
알테라(Altera)의 Quartus Ⅱ 개발 소프트웨어는 타이밍 클로저에 관련된 문제들을 해결할 수 있도록 설계된 툴들을 포함한다(주요 자원의 이용 가능성, 로컬 및 전역 라우팅 혼잡의 정도, 클록 네트워크의 스큐로 인해 발생할 수 있는 타이밍 위반을 방지하도록 로직을 정확하게 타이밍하는 등). 그런데 많은 경우에 간단한 HDL 변경만으로 타이밍 문제를 해결하는 데 매우 효과적일 수 있으며 원하는 타이밍 클로저를 달성하는 데 걸리는 시간을 단축할 수 있다. 이 글에서는 이와 같이 가능한 HDL 변경과 이러한 변경이 FPGA의 아키텍처 및 레이아웃에 대해서 갖는 관련성에 대해서 살펴본다. 이 글은 모든 타이밍 문제에 대해서 포괄적으로 살펴보려는 것이 아니라, 우수한 코딩 규칙에 관한 가이드라인을 제시하고 이러한 우수한 규칙을 알테라 28 nm 디바이스에서 구현한 설계에 어떻게 적용할 수 있는지 설명한다.
타이밍 최적화 - 최단 경로 찾기
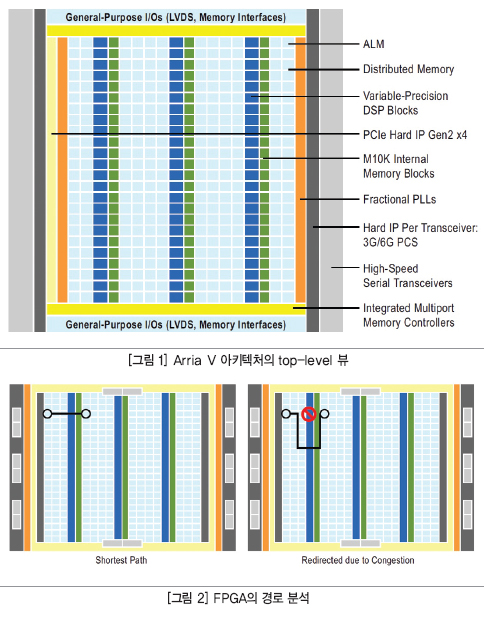
그림 1은 알테라 Arria V FPGA 아키텍처의 최상층 뷰를 보여주고 있다. FPGA의 모든 자원은 행과 열로 이루어진 행렬로 배치된다. 디바이스의 상단과 하단에는 I/O가 배치되고 왼쪽과 오른쪽 측면에는 SERDES(Serial
izer/Deserializer) 트랜시버가 배치된다. 트랜시버가 배치되는 측면과 FPGA의 중앙에는 분주형 PLL
(Fractional Phase-Locked Loop)이 배치된다. DSP(Digital Signal Processor), ALM(Adaptive Logic Module), 메모리는 FPGA 전체에 분산된다. 이러한 자원의 열(column) 맵핑은 알테라의 모든 유형의 28 nm 제품에 해당되는 것이며, 해당 FPGA 기능에 따라서 각기 필요한 자원들(열)을 조합할 수 있다.
FPGA 레이아웃은 주기적으로 반복되는 자원 행렬로서 상호 접속된 패브릭 메시(mesh)를 통해서 액세스할 수 있다. 다시 말해, 이들 자원은 일련의 수평 및 수직 패스웨이를 이용해서 상호 연결된다. 그림 2에서 보듯이 피터(fitter)는 항상 디바이스에서 가능한 최단 경로를 선택하려고 하지만, 종종 그 경로를 설계 내의 다른 요소가 이용하고 있어서 이용하지 못하게 된다.
피터는 오늘날 대다수 자동차에 이용되는 GPS처럼 동작한다. 피터는 이용 가능한 자원과 그 자원에 대해서 부여된 제약에 따라서 각기 다른 경로 중에서 가장 짧은 경로를 선택하려고 한다. 피터가 선택하는 경로는 얼마나 많은 경로 중에서 선택해야 하고 얼마큼의 거리를 이동해야 하는지에 따라 달라진다.
Tip 1 - 고속도로가 반드시 가장 빠른 길은 아니다(로직 리 타이밍)
28 nm FPGA는 메시 내에 설치할 수 있는 자원의 양이 크게 증가했다. 디바이스의 로직 엘리먼트(LE)가 100K에 불과했던 시절은 지나갔다. 현재 디바이스들은 1M LE에 이르고 있는데, 기본적인 인터커넥트 메시는 여전히 그대로다. 이것은 다시 말해 셀 지연은 빨라지고 있고 인터커넥트 지연은 느려지고 있음을 의미한다. 다시 GPS에 비유하자면, 간선 도로(인터커넥트)는 훨씬 많은 차들이 진입하려고 경쟁하다보니 혼잡이 심해져 때로는 지선 도로(로컬 셀 배선)를 이용하는 것이 훨씬 빠르게 된 꼴이다. 어느 대도시에서든 교통이 혼잡한 러시아워에 운전을 해본 사람이라면, 이러한 혼잡한 시간에 간선 도로를 택하지 않으려고 하는 심정을 이해할 것이다.
혼잡을 피할 수 있는 한 가지 방법은 주요 경로 상의 주요 자원들을 되도록이면 동일 셀 내에 배치하는 것이다. 신호가 이동해야 할 거리가 짧을수록 혼잡이 발생할 수 있고, 그럼으로써 경로 지연을 일으킬 수 있는 긴 인터커넥트 라인을 사용할 가능성이 줄어드는 것이다. 이를 달성하기 위해서 가장 좋은 방법은 HDL 코드를 평가하고 큰 덩어리의 로직을 작은 조각들로 분할하고 각기 다른 조각들 사이의 의존성을 제한하는 것이다. 문제가 발생할 것인지에 대한 좋은 지표가 되는 것이 타이밍 경로의 지점들 사이에 존재하는 로직 레이어의 수이다. 로직 레벨이 많을수록 어떤 기능을 수행하기 위해서 이용되는 자원들이 인접해 있을 가능성이 낮아진다. 자원들이 디바이스 상에 흩어져 있을수록 이들 자원에 도달하기 위해서 인터커넥트 경로를 더 많이 이용해야 한다.
Tip 2 - 러시아워를 피하라(공격적 파이프라이닝)
다시 GPS에 비유하자면, 어느 도시의 A 지점에서 B 지점으로 가기 위해서 걸리는 시간은 하루 중 어느 시간대냐에 따라 크게 달라진다. 만약, 일과를 마치고 집으로 돌아가는 시간이라면, 이 시간에는 많은 사람들이 귀가하는 시간이기 때문에 혼잡할 가능성이 그만큼 커진다. 그런데 같은 길이라도 한밤중에는 대부분의 사람들이 잠든 시간이므로 교통이 매우 한산할 것이다. FPGA 설계에서 혼잡을 관리하기 위한 가장 좋은 방법은 설계를 파이프라이닝하는 것이다.
설계를 파이프라이닝하면, 시스템에 지연시간이 추가되지만 실제적으로 클록과 데이터의 관계를 변화시켜서 이들이 목적지에 동일한 시간에 도착하도록 함으로써 타이밍 문제가 일어나는 것을 방지할 수 있다. 파이프라이닝은 클록에서 볼 수 없는 더 긴 인터커넥트 지연의 영향을 줄일 수 있다. 클록은 데이터나 로직과는 다른 별도의 경로 네트워크를 따라서 이동하므로 클록이 도착할 것으로 예상되는 시간보다 빠르거나 늦게 데이터가 도착하면 타이밍 문제가 발생할 수 있다.(이러한 것들을 흔히 셋업 및 홀드 위반이라고 한다.) 경로에 파이프라인 레지스터를 삽입하면, 신호를 재 타이밍함으로써 클록과 데이터가 로직의 다음 부분에 같은 시간에 도착한다. 이러한 방법이 긴 인터커넥트 지연을 다루기 위한 방법으로서 선호되고 있으며 타이밍 위반을 방지하기 위한 편리한 방법이다.
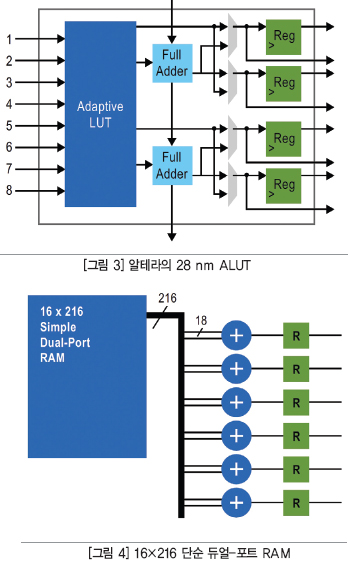
알테라는 대형 FPGA에 좀 더 많은 파이프라이닝이 필요함을 인식하고 2개의 레지스터를 추가로 포함하도록 LE와 ALUT(Adaptive Look-Up Table)를 재설계했다(그림 3). 여기에는 두 가지 이유가 있다. 첫째, 추가적인 레지스터들이 더 많은 레지스터 자원을 제공하므로 정상적인 로직 기능으로 추가적인 파이프라인 레지스터를 필요로 하는 문제를 해결할 수 있다. 이전에는 파이프라인 레지스터를 이용해서 설계를 재 타이밍하려면, ALUT가 낭비됐다. 둘째, 이렇게 변경함으로써 파이프라인 레지스터와 이것이 목표로 하는 로직을 인접하게 배치할 수 있다. 인접하게 배치하는 것이 중요한 이유는 파이프라인 레지스터가 긴 인터커넥트 지연을 제거하는 데 사용되기 때문이다. 만약, 파이프라인 레지스터를 로직과 같은 셀에 배치하지 않으면, 데이터가(예를 들어, 디바이스의 반대편에 배치되어 있는) 레지스터로 갔다가 다시 ALUT로 돌아와야 하기 때문에 또 다른 인터커넥트 지연을 일으킬 것이다. 이와 같은 추가적인 레지스터를 이용함으로써 파이프라인 레지스터를 로직과 인접하게 배치할 수 있으므로 시스템 내의 지연을 최소화할 수 있다.
파이프라이닝의 이점
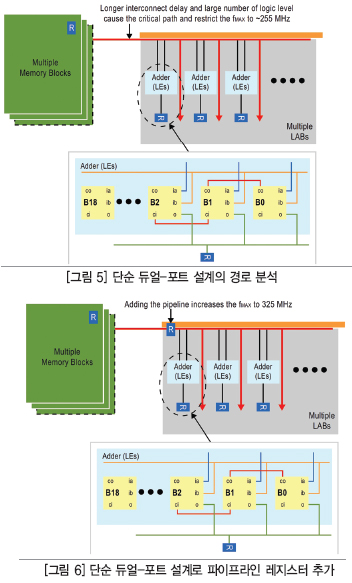
이 예제는 Arria V 360K LE 디바이스에 예시된 16비트×256비트 단순 듀얼-포트 RAM에 관한 것이다(그림 4). RAM-대-다중 LE의 높은 팬아웃으로 인해, 이 경로의 속도는 255 MHz로 제한됐다.
그림 5의 설계 분석은 RAM과 덧셈기 사이의 인터커넥트 지연이 시스템 전체 지연의 54%를 차지하고 있음을 보여준다.
그림 6에서 보듯이, 로직 앞에 단일 파이프라인 레지스터를 삽입해서 상당한 인터커넥트 지연을 제거함으로써 설계를 325 MHz로 실행할 수 있게 된다. 그렇게 해서 달성되는 70 MHz의 차이는 설계에서 단일 파이프라인 레지스터를 삽입하는 것만으로 성능을 27% 향상시키는 것에 해당한다.
Tip 3 - 가급적 카풀(car pool)을 실시하라(높은 팬아웃 노드 방지)
로직 내에서는 흔히 동일한 신호가 같은 시간에 여러 위치에 도착해야 한다. 이 신호를 동일한 자원으로부터 보내는 것이므로 피터는 모든 신호 복제에 대해서 적합한 경로를 탐색하고, 이들 모두가 각기 위치에 같은 시간에 도착하도록 해야 한다. 이러한 상황을 팬아웃이 높은 노드라고 하는 것이며 그림 4에서 보는 것과 같다. 문제는 모든 신호가 각기 목적지에 같은 시간에 도착하도록 하기가 어려울 수 있다는 것이다. 이것은 5개의 신호 복제 모두가 각기 목적지에 도착하기 위해서 동일한 라우팅 자원을 이용할 수 있는 것이 아니고 각기 목적지가 디바이스의 각기 다른 위치에 있을 수 있기 때문이다. 이 문제를 피할 수 있는 가장 좋은 방법은 노드 복제(node replication)를 이용하는 것이다.
노드 복제는 수작업으로 하거나 툴을 이용해서 자동으로 할 수 있다. 예를 들어, 20개의 동일한 복제 신호는 동일한 로직에 같은 시간에 도착해야 한다. 이 모든 20개 경로가 정확하게 일치하고 타이밍을 준수하도록 하는 것은 극히 어려운 일일 수 있다. 설계가 전체 공간의 많은 부분을 차지할 때는 더욱 더 그렇다. 노드 복제를 이용해서 설계를 2개 스테이지로 쪼갤 수 있다. 첫 번째 스테이지는 1-대-4 팬아웃이고, 두 번째 스테이지는 1-대-5 팬아웃일 수 있다. 이 두 스테이지를 합치면 동일하게 1-대-20 팬아웃을 달성하면서도 2개의 각기 분리되어 있으면서 좀 더 관리가 용이한 문제로 쪼갤 수 있다. FPGA로 20개 경로를 일치시키는 것보다 4개나 5개 경로를 일치시키기가 훨씬 수월할 것이다.
혼잡 줄이기
지금까지 설계에서 타이밍 문제를 방지하기 위해 로직을 재 타이밍하는 방법에 대해서 설명했다. 이 부분과 다음 부분에서는 설계를 시작하기에 앞서 고려해야 할 구조적인 문제들에 대해서 살펴보려고 한다. 첫 번째 문제는 FPGA의 혼잡으로서, 혼잡은 그것이 클록 자원이든 인터커넥트 라인이든, 과도하게 많은 LE가 동일한 자원을 두고 경쟁할 때 일어난다. 피터는 각기 다른 LE의 필요들을 조정해야 하므로, 이용하는 LE가 많을수록 피터가 최적의 경로를 선택하기 위해서 이용할 수 있는 옵션이 적어진다. 전체 공간의 85% 이상을 차지하고 있는 설계는 50%만 차지하는 설계에 비해서 타이밍을 만족하기 어려울 것이다. 알테라의 패브릭은 최대 90%까지 차지하는 설계도 가능하지만, 이러한 설계 상에서 타이밍 클로저를 보증하기 위해서는 주의가 필요하다. 매우 혼잡한 설계에서 타이밍을 향상시키기 위한 몇 가지 방법이 있다. 그것은 파티셔닝을 이용하는 것과 클록 네트워크를 관리하는 것이다.
Tip 4 - 사고는 넓게, 행동은 좁게 (파티셔닝과 계층적 설계)
계층적 설계는 FPGA 설계에서 여러 가지 이점을 제공한다. 첫째, 설계를 작은 블록들로 파티셔닝 할 수 있다. 파티셔닝을 하면, Quartus Ⅱ 소프트웨어에 포함된 툴로서 신속한 점증식 재 컴파일 기능을 이용할 수 있다. 이 기능을 이용하면, 사용자가 설계의 일부만 재 컴파일할 수 있다. 이 툴은 피터가 변경된 설계 부분만 다룰 수 있으므로 라우팅 문제를 간소화하고 설계의 나머지 부분은 변경하지 않고 그대로일 수 있다는 점에서 매우 유용하다.
피터가 설계의 모든 경로를 고려하지 않아도 되므로 타이밍 클로저가 더 수월해진다. 이와 달리 사용자가 전체적인 설계를 컴파일 할 때는 피터가 모든 의존성을 고려해야 한다. 이 방법은 설계를 컴파일할 때마다 루트가 각기 달라지고 각기 다른 타이밍 결과를 야기할 수 있다. 피터가 설계의 어떤 것이 변경되었고 변경되지 않았는지 알지 못하므로 모든 것이 변경된 것으로 간주하고 알고리즘을 이용해서 전체적인 설계를 재정비하려고 한다.
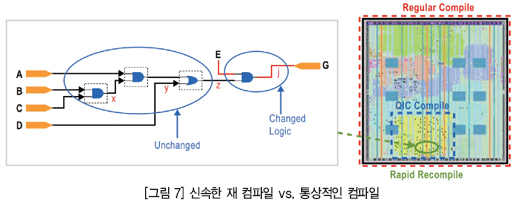
또한 신속한 재 컴파일을 이용하면, 변경된 부분만 재 라우팅하므로 설계의 전체적인 컴파일 시간이 줄어든다. 그림 7은 설계의 일부와 여기에 대해서 어떻게 신속한 재 컴파일 기능을 이용할 수 있는지 보여주고 있다. 한 파티션은 단일 ALUT만큼 작을 수도 있고 전체 디바이스만큼 클 수도 있다.
트래픽 관리
두 번째 구조적 기법은 알테라의 Qsys 시스템 통합 툴 같은 시스템 테스트베드 툴을 이용할 수 있도록 계층적 설계를 이용하는 것이다. Qsys를 이용하면, 사용자가 각기 다른 IP(Intellectual Property) 블록을 빠르고 편리하게 연결하고, 이들을 알테라의 디버깅 IP 스위트로 통합할 수 있다. 이렇게 통합하면, 전체적인 시스템의 가상 테스트가 가능하며 설계의 성능과 기능성을 평가할 수 있다. 파티셔닝은 IP를 각기 다른 블록으로 쪼개서 Qsys 및 전체적인 계층적 설계 플로로 통합할 수 있는 훌륭한 방법이다. 파티셔닝의 또 다른 이점은 설계 재사용이다. 이것은 IP를 블록으로 유지할 수 있으며 각기 다른 위치에서 전체 설계의 각기 다른 부분을 맡아서 작업할 때 동일한 라우팅, 성능, 다중 위치 설계 작업을 유지할 수 있기 때문이다.
Tip 5 - 열차가 정시 운행하도록 하라(클록 스큐와 클록 네트워크 관리)
알테라의 FPGA는 6개 유형의 클록을 이용한다: GCLK, QCLK, PCLK, SCLK, ROWCLK, VIOCLK. ROWCLK부터 GCLK까지의 각각의 클록은 순차적으로 디바이스의 더 넓은 영역을 다루는 것들이다. 인터커넥트는 레인에 액세스하기 위해서 경쟁하는 자원의 양 때문에, 레인이 길어지는 것을 피하도록 제안했지만 클록은 숫자가 소수이다. GCLK 같은 클록 라인은 크기가 클수록 클록을 더 빠르게 전달할 수 있으므로 클록 스큐를 제한하고 셋업 및 홀드 타이밍을 향상시킬 수 있다.
PLL에서 내부 자원으로 클록 신호를 되도록 빠르게 전달하는 것이 좋다. 이것은 다시 말해 ROWCLK 같은 로컬 클록 네트워크에서 QCLK나 GCLK 같은 상위 클록 네트워크로 즉각적으로 전환하는 것을 말한다. 이것을 클록 승격(promotion)이라고 하는데, 이것은 피터가 자동으로 실시하려고 시도한다. 소프트웨어 설계 제약(software design constraint) 파일 때문에, 클록이 제한되어 있을 때는 사용자가 가능한 곳마다 클록이 승격되도록 해야 한다.
타이밍 클로저의 복잡성
계획이 훌륭하고 HDL 코드가 훌륭하더라도 원하는 타이밍을 달성하기가 어려울 수 있다. 특히, 규모가 큰 설계일 경우는 더욱 더 어려운 문제일 수 있는데, 이러한 설계는 모든 루트를 이해하고 어느 루트가 타이밍 향상으로 이득을 볼 수 있을 지 판단하기 위해서 시간이 많이 걸리기 때문이다. 또한 어떤 상황에서는 단순히 어떠한 향상이 가장 유용할 것인지 이해하는 것조차 어려운 문제일 수 있다.
Tip 6 - 방향을 물어라(알테라의 자동화 타이밍 클로저 분석 툴)
알테라의 Quartus Ⅱ 소프트웨어 내의 TimeQuest 타이밍 분석기를 통해서 자동화 타이밍 클로저 분석 툴을 실행할 수 있다. 이 툴은 디자이너에게 일련의 권장사항을 제시함으로써 조언을 제공하도록 설계된 것으로서 사용자는 이러한 제안을 평가하고 시도할 가치가 있는지 판단할 수 있다. 이러한 제안은 완벽한 것이 아니다. 이 툴은 변경이 실현 가능한 것인지, 시도하기가 용이한 것인지 알지 못하기 때문이다. 이 툴은 설계의 어떤 부분을 사용자가 재검토해야 할 것인지 알 수 있도록 하며 어떠한 변경이 그 회로에 가장 유익한 지 알려준다.
이 툴의 전반적인 취지는 사용자에게 유용한 조언을 제공하는 것이다. 타이밍 문제를 어디서부터 살펴봐야 할지 알 수 없는 경우가 흔하기 때문이다. 이 툴은 다음과 같은 타이밍 문제들을 살펴보고 조언을 제공한다:
- 높은 클록 스큐
- Quartus Ⅱ 소프트웨어가 재 타이밍이나 복제(duplicate)를 할 수 없는 최적화 제한
- 경로를 재 타이밍하는 것이 유익할 것 같은 불균형적인 로직
- 경로 상의 노드가 non-overlapping 구역으로 동기화되어 있는 구역 제약
- 경로가 파티션 경계를 통과할 때 발생하는 파티션 제약
- 특정한 타이밍 제약에 대해서 너무 많은 로직
- 중요한 로직에 제어 신호 경로 이용
- 피터가 해당 경로를 중요한 것으로 인식하지 않음으로써 Quartus Ⅱ 소프트웨어가 최적화 대상으로 고려하지 못하는 것
- 경로 간 경쟁
이 툴은 각각의 문제와 그에 따른 제안을 설명하는 링크를 제공한다. 또한 이러한 제안에 대해서 별의 숫자를 이용해서 순위를 매김으로써 사용자는 시스템의 타이밍에 가장 크게 영향을 미치는 제안에 중점을 둘 수 있다.
<저작권자(c)스마트앤컴퍼니. 무단전재-재배포금지>



