



비디오 및 이미징 애플리케이션에 사용하기 위한 고집적 프로그래머블 FIFO 메모리
비디오 방송, 군사, 의료 이미징, 기지국 등을 포함한 많은 시장 영역은 프로그래머블 기능을 가진 고집적 FIFO 디바이스 솔루션의 사용에서 이점을 누릴 수 있다. SDRAM + FPGA 아키텍처 와 비교하여 상당한 비용 절감 효과와 향상된 영상 품질을 제공하는 것 이외에 고집적 FIFO 설계의 복잡성과 비용은 시스템-레벨 프로그램 능력을 이용하여 보다 잘 해결할 수 있다.
자료 : 싸이프레스
본 글에서 우리는 필요로 하는 데이터 경로의 이해와 데이터 처리의 성격을 가지는 몇 가지 비디오 애플리케이션을 먼저 고려할 것이다. 다음 단계로 우리는 어떠한 영상 프로세싱 파이프라인에서 데이터 처리의 복잡성을 계산하고자 할 것이다. 프로그래머블 고집적 FIFO는 기능과 함께, 그리고 SDRAM 과 FPGAs를 이용하여 프레임 버퍼의 기존의 전통적인 구현에 보다 효율적인 대안으로서 프로그래머블 고집적 FIFO가 어떻게 역할을 할 수 있는지가 소개될 것이다.
비디오 애플리케이션 개요
<그림 1>은 IPTV의 시스템 블록 다이어그램을 보여주고 있다. DVB-ASI, MPEG2 혹은 SDI와 같은 어떠한 인코딩 포맷에서의 입력 전송 스트림은 H.264 전송 스트림으로 변환되는 (즉, decoded와 re-encoded) 멀티-포맷 CODEC을 통해 전달된다. 인코딩 된 전송 스트림은 채널 정보와 함께 캡슐화 되며 이더넷을 통해 보내진다. 수신 경로에서 들어오는 전송 스트림은 디코딩 되며, 소음 감소, 색상 강화, 스케일링, 드-인터레이싱(de-interlacing) 등과 같은 post-processing은 디스플레이 전에 완료된다.
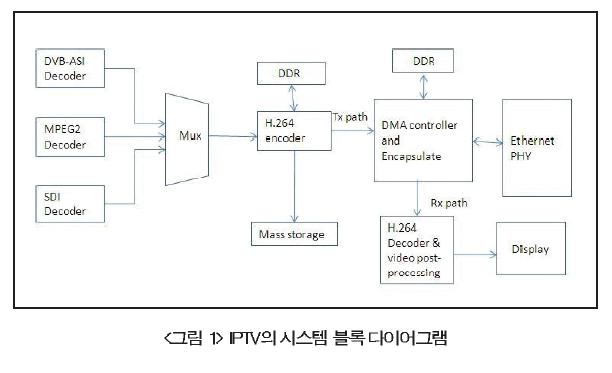 <그림 2>는 영화 제작 및 스튜디오에서 사용된 전문가용 고화질 카메라의 시스템 블록 다이어그램을 보여주고 있다. 캡처 된 이미지는 색상 처리, 밝기 향상, 디지털 줌, 프레임 레이트 변환 등을 하는 이미지 처리 장치를 통해 전달된다. 이러한 이미지 처리 장치는 대부분의 이미지 처리가 독점이고 자주 변화함에 따라 일반적으로 FPGA를 기반으로 한 설계이다. 애플리케이션 프로세서는 다른 장비로 통신을 관리하며, 대용량 스토리지(HDD)에 캡처한 콘텐츠를 압축하고 저장한다. 애플리케이션 프로세서는 또한 애플리케이션 프로세서는 또한 들어오는 동영상이 표시되도록 혼합하는 on-screen display(OSD)를 생성하는 그래픽 엔진을 가지고 있다.
<그림 2>는 영화 제작 및 스튜디오에서 사용된 전문가용 고화질 카메라의 시스템 블록 다이어그램을 보여주고 있다. 캡처 된 이미지는 색상 처리, 밝기 향상, 디지털 줌, 프레임 레이트 변환 등을 하는 이미지 처리 장치를 통해 전달된다. 이러한 이미지 처리 장치는 대부분의 이미지 처리가 독점이고 자주 변화함에 따라 일반적으로 FPGA를 기반으로 한 설계이다. 애플리케이션 프로세서는 다른 장비로 통신을 관리하며, 대용량 스토리지(HDD)에 캡처한 콘텐츠를 압축하고 저장한다. 애플리케이션 프로세서는 또한 애플리케이션 프로세서는 또한 들어오는 동영상이 표시되도록 혼합하는 on-screen display(OSD)를 생성하는 그래픽 엔진을 가지고 있다.
 위의 사례에서 우리는 2가지 유형의 데이터 처리가 개입되어 있다는 것을 볼 수 있다.
위의 사례에서 우리는 2가지 유형의 데이터 처리가 개입되어 있다는 것을 볼 수 있다.
▶프레임 동기화 :
프레임 동기화는 디코더가 일정한 bit-rate 전송 스트림을 필요로 하는 반면 bit-rate 가 계속 변하는 이더넷을 통한 전송 및 수신 등과 같은 작업에 필요하다. 동기화에 필요한 메모리가 작아 보일 수도 있지만 이는 다중 스트림이 관여할 때 의미가 있을 수 있다. 이러한 동기화는 비동기 FIFO로 달성된다.
▶프레임 스토리지 :
프레임 스토리지는 프레임 속도 변환, 디지털 줌(스케일링), 또는 드-인터레이싱 같은 어떠한 시간 신호 처리가 수행될 때마다 필요하다. 저장되는 프레임의 수는 필요로 하는 시간 신호 처리의 양과 함께 증가한다. 비디오 데이터는 성격상 순차적이므로 프레임 버퍼는 기본적으로 FIFO여야만 한다.
위의 논의로부터 우리는 모든 스토리지와 동기화는 FIFO를 이용하여 달성될 수 있다고 말할 수 있다. 필요로 하는 이러한 FIFO의 크기에 대한 아이디어를 제공하기 위해 10-bit 4:2:2 포맷에서의 일반적인 1080p 프레임은 39.55Mbit의 메모리 크기를 필요로 할 것이다(라인 당 픽셀의 수 * 프레임 당 라인의 수 * 픽셀 당 bits의 수 = 1920*1080*20). 전체 크기는 저장해야 할 프레임의 수에 의해 이러한 숫자를 곱함으로써 계산할 수 있다.
일반적인 동영상 처리 알고리즘은 2~3 프레임이 저장되는 것이 필요하며, 이는 전체 크기가 최고 120Mbit가 될 수 있다는 것을 의미한다. FIFO 메모리를 기반으로 한 이 같은 대형 온-칩 SRAM을 가지는 것이 가능하지 않음에 따라 일반적인 접근방식은 이러한 데이터에 버퍼하기 위해 DRAM을 이용하는 것이다.
고집적 FIFO - 전통적인 구현과 복잡성
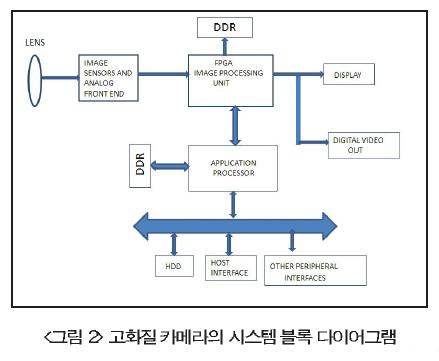
프레임 버퍼는 아무것도 아니지만 고집적 FIFO이며 통상 이들은 외부 DDR SDRAM을 이용하여 구현된다. 일반적인 동영상 처리 애플리케이션과 이러한 FIFO가 어떻게 구현되는지를 고려한다.그림 3>은 서로 다른 소스에서 4개의 비디오 스트림이 싱글 디스플레이에 표시되는 일반적인 시나리오에 대한 데이터 경로를 보여주고 있다. 1080p60(24-bit RGB) 화질로 동영상 을 캡처하는 4개의 고화질 카메라는 카메라 링크 인터페이스를 이용하여 시스템에 연결된다. 색상 공간 변환 (RGB에서부터 YCbCr까지)과 chroma 다운 샘플링 (4:4:4 to 4:2:2) 이후 프레임은 수평과 수직 두 가지 모두의 비율로 다운 스케일 되며, DDR2 SDRAM 메모리에 저장 된다. 저장된 프레임은 다시 읽기로 필요한 곳에 위치하며, 병합 메모리 프레임으로 인한 프레임은 샘플-업 되고 색상 공간은 LVDS 링크를 통한 패널을 구동하기 위해 변환된다. 이제 필요로 하는 메모리 크기와 대역폭을 보자:
▶필요한 크기 :
효과가 분산되는 것을 피하기 위해 시간 신호 처리 기능이 관여하지 않음에도 각 소스의 두 프레임은 저장되며 따라서 하나의 프레임이 쓰이고 있을 때 다른 하나는 다시 읽혀질 수 있다. 두 프레임의 크기는 ((1920*1080*16)/4)*2 ~= 63.3Mbit이다.
▶필요한 대역폭 :
읽기 및 쓰기 경로가 다중 송신됨으로써 필요한 대역폭은 쓰기 및 읽기 경로 대역폭의 합계이다.
쓰기 경로 주파수 = (각 클라이언트의 주파수)*(클라이언트의 수) = (148.5/4)*4 =148.5MHz
읽기 경로 주파수 = 출력 프레임 해상도 주파수 = 148.5MHz.
인터페이스는 이중 데이터 속도로 작동함으로써 실제 작동 주파수는 ((읽기 주파수 + 쓰기 주파수)/2 + 오버헤드) 일 것이며, DRAM 메모리 리프레쉬 사이클, 뱅크 어드레스 스위칭 등과 같은 오버헤드가 있다. 80% 효율을 가정하면 작동 주파수는 185MHz 정도일 것이다.
▶필요한 메모리 인터페이스 크기 및 I/O :
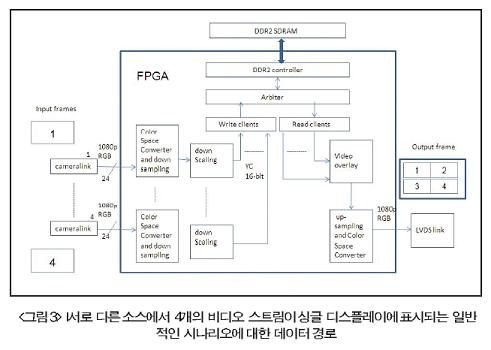 프레임이 16-bit 4:2:2 포맷에 저장됨으로써 16-bit 인터페이스로 충분하다. FPGA 에서 필요로 하는 I/O의 총수는 46 pin 일 것이며 다음과 같이 계산된다.pins (차동 클록을 위해 2, 클록 활성화를 위해 = 3 pinspins (칩 선택, RAS, CAS, WE) = 4 pinspins (14 address lines, 3 bank address lines) =17 pinslines (X16 인터페이스) = 16 pinsstrobe & mask (2개의 차동 DQS를 위한 4 pins, data mask를 위한 2 pins) = 6 pins
프레임이 16-bit 4:2:2 포맷에 저장됨으로써 16-bit 인터페이스로 충분하다. FPGA 에서 필요로 하는 I/O의 총수는 46 pin 일 것이며 다음과 같이 계산된다.pins (차동 클록을 위해 2, 클록 활성화를 위해 = 3 pinspins (칩 선택, RAS, CAS, WE) = 4 pinspins (14 address lines, 3 bank address lines) =17 pinslines (X16 인터페이스) = 16 pinsstrobe & mask (2개의 차동 DQS를 위한 4 pins, data mask를 위한 2 pins) = 6 pins
이산 메모리 (discrete memory)로서의 고집적 FIFO
이제 이산 프로그래머블 고집적 FIFO를 이용하여 구현하는 것과 DDR2 SDRAM 메모리가 데이터 스토리지를 단순화하기 위해 대체될 수 있는 기능 설정을 살펴보자.
▶멀티-큐 (multi-queue) 기능 :
메모리를 하나의 메모리 덩어리로 정의한다면 다중 비디오 스트림을 작성하는 것은 불가능하다. 따라서 FIFO는 multiple queue로 구성되고 나눠질 수 있어야만 한다. 예제 시나리오에서 쓰기를 위한 4가지 다른 프레임이 있으며, 동시에 4가지 프레임은 다른 queue로부터 읽어야 한다. 따라서 우리의 애플리케이션은 최소 8개의 queue가 필요하다.
▶마크 (Mark)와 재전송 :
데이터를 일단 표준 FIFO에서 읽으면 FIFO에서 상실된다. 다시 프로그램 될 수 있는 FIFO 포인터의 여부는 어떠한 프레임도 필요로 하는 한 여러 번 읽을 수 있다.
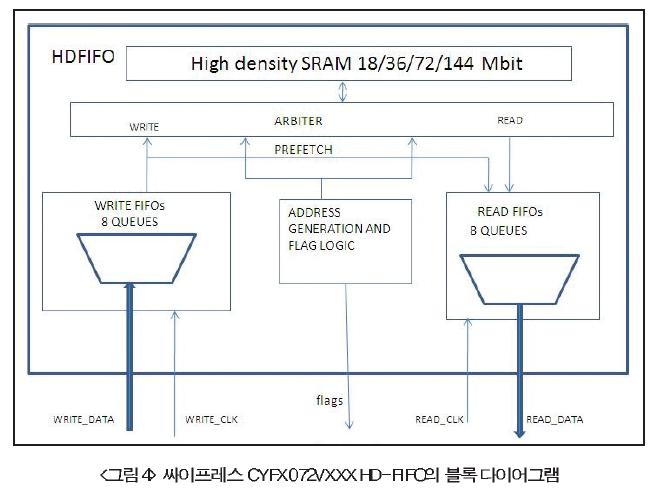
그림 4>는 싸이프레스 CYFX072VXXX HD-FIFO의 블록 다이어그램을 보여주고 있으며, <그림 5>는 DDR2 칩을 대체하는
<저작권자(c)스마트앤컴퍼니. 무단전재-재배포금지>



