



글 | 마크 캔트렐(Mark Cantrell) & 비키란 고스와미(Bikiran Goswami) 아나로그디바이스
센서 애플리케이션에서 오버샘플링이 동적 범위를 늘리기 위해서는 해당 주파수와 비교해 샘플링 주파수를 크게 높여 잡음을 줄여야 한다. 이글에서는 절연 SPI 인터페이스의 쓰루풋을 향상하고 샘플레이트를 높이는 지연 클록 기법에 대해 설명한다.
직렬 주변기기 인터페이스(Serial Peripheral Interface, SPI) 버스는 여러 이유에서 설계자들이 즐겨 사용하고 있다. SPI 버스는 회로 기판 내에 칩 간의 거리가 최소일 때, 최대 60 Mbps의 빠른 속도로 데이터를 전송할 수 있다.
SPI 버스는 개념적으로 단순하며 클록 한 개, 데이터 라인 두 개, 칩 선택 신호 한 개로 이뤄졌다. 데이터는 클록의 한 쪽 위상에 존재하며 반대쪽 위상에서 다시 읽기 때문에 속도 측면에서 지연 및 불일치에 대한 특성에 많은 마진을 가진다. 결국 SPI 버스는 무지향성 라인으로 구성되기 때문에 이를 사용하면 흐름 제어 문제가 사라져 마이크로프로세서 내에서의 구현이 간소화된다.
기존의 절연 장치들은 대부분 무지향성으로 SPI 버스는 광커플러나 디지털 절연기를 사용하는 절연 방식에 적합하다. 또한 온도나 압력 모니터링 시스템과 같은 산업 애플리케이션에서 센서의 프런트 엔드에 위치한 A/D 컨버터와의 통신에서는 샘플레이트가 높을 필요가 없으며 SPI 클록 속도 역시 높지 않아도 된다. 절연 설계조차 다양한 절연 기술에서 간단히 구현된다. 하지만 이에 대한 필수 요건들은 시대에 따라 변화하고 애플리케이션이 긴 전송 거리, 높은 데이터율, 무엇보다 높은 절연 요건을 요구함에 따라 SPI 인터페이스는 그 한계를 넓혀왔다.
절연 SPI 성능의 한계를 시험하는 애플리케이션은 높은 동적 범위 센서 인터페이스이다. 설계자는 넓은 동적 범위를 갖춘 시스템을 개발하기 위해서 뛰어난 SNR(signal-to-noise ratio)을 갖춘 A/D 컨버터에서부터 시작할 수 있다. SNR은 일반적으로 단어 길이와 연관되어 있으며 16비트 단어가 일반적이다. 높은 동적 범위가 필요한 경우, 입력의 가변 이득 증폭과 오버샘플링 같은 다른 기법들을 사용할 수 있다. 오버샘플링은 잡음 제거를 위해 대역폭을 활용한다.
.jpg)
샘플 주파수가 두 배가 되면 잡음 성능이 보통 3 dB 향상된다. 예를 들어 오버샘플레이트가 75배라면 잡음 성능과 동적 범위는 약 18 dB 향상된다. 다시 말해 신호를 75배 오버샘플링하면 900 ksps에서 작동하던 A/D 컨버터가 약 6 kHz 대역폭에서 18 dB 향상된 동적 범위를 제공한다. 대역폭과 동적 범위는 반비례 관계인 경우도 물론 있지만, A/D 컨버터의 속도를 최대한 높일 경우 결국 그 이점은 매우 커진다.
이는 SPI 버스가 엄청난 대량의 데이터를 처리해야만 한다는 것을 뜻한다. 높은 샘플레이트의 애플리케이션에 사용되는 ADI의 AD7985 pulSAR A/D 컨버터 같은 일반적인 부품을 예로 들어보자. 이 제품의 최대 전송 속도는 2.5 Msps이다. 우리는 SPI 버스를 통해 이 부품과 통신하는 방식이 신호 체인의 성능에 어떠한 영향을 미치는지 알아볼 것이다.
A/D 컨버터 인터페이스
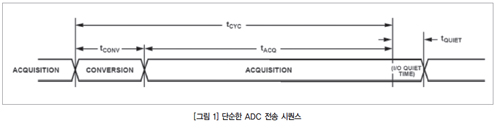
일반적인 A/D 컨버터는 두 가지 기본적인 작업에서 데이터를 처리한다(그림 1). 먼저 A/D 컨버터는 변환 시간(tCONV)동안 입력 시 전압을 표시하는 디지털 단어를 생성하고 그 후 수집 시간(tACQ)동안 디지털 인터페이스를 통해 이 단어를 컨트롤러에 전송한다. 보통 A/D 컨버터가 다시 변환을 시작하기 전에 최소 사이클 시간(tCYC)이 지나야 하며 이는 대략 tCONV와 tACQ의 합과 같다. A/D 컨버터가 수집과 전송이 겹쳐지는 특별한 전송 모드를 사용하는 경우 tCYC가 더 짧아지기도 한다. 그러나 논의의 간결함을 위해 여기에서는 차례로 변환과 수집이 일어나는 경우만을 다루기로 한다.
변환 시간과 최소 사이클 시간은 데이터의 전송 방식과 관계없이 같다. 하지만 수집 시간은 데이터 인터페이스의 특징, 그 중에서도 대부분 SPI 버스의 작동에 좌우된다. SPI 클록 속도 때문에 수집 시간이 늘어난다면 A/D 컨버터의 샘플레이트가 크게 제한될 수 있다.
SPI 클록 속도 제한
그림 2는 마이크로프로세서/FPGA(MCU)와 A/D 컨버터 사이의 SPI 연결을 나타낸 것이다. SPI 버스는 시프트 레지스터 두 개 사이의 연결로 이뤄졌으며 각각은 마스터 MCU에 하나, 슬레이브 A/D 컨버터에 하나씩 위치한다. MCU는 전송을 동기화하는 클록을 생성한다. 클록의 한쪽 끝은 시프트 레지스터에서 데이터를 시프트하고 반대쪽 끝에서는 링 토폴로지에서 각각의 시프트 레지스터의 다른 끝에 존재하는 데이터에 클록을 부여한다.
A/D 컨버터의 경우 MCU에서 A/D 컨버터로 데이터를 시프트하지 않아도 될 수 있으므로 이 채널은 논의의 간결함을 위해 슬레이브 선택과 마찬가지로 생략하기로 한다. A/D 컨버터는 동작의 변환 단계에서 내부 시프트 레지스터의 역할을 하며 수집 단계에서 레지스터를 시프트-아웃한다.
SPI 트랜젝션에서는 마스터에서 생성된 클록 신호가 배선 지연을 거쳐 슬레이브로 이동하며 이때 슬레이브는 약간의 내부 지연 후에 데이터를 시프트-아웃한다. 데이터 신호는 다시 한 번 배선 지연을 거쳐 마스터로 돌아오는데 클록의 반대쪽 끝에 제시간에 도착해야 한다. 마스터의 경우 보통 준비 시간 요건이 추가된다.
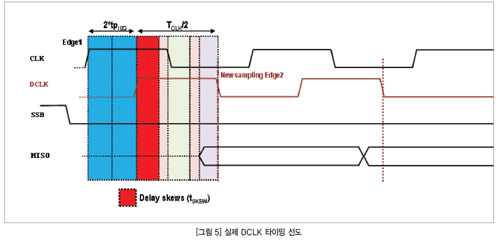
그림 2는 이러한 지연이 마스터 클록 주기의 절반에 해당하는 최소 시간을 달성하는 방법을 보여준다. 비절연 시스템에서 지연은 보통 매우 짧으며 대부분의 경우 10 nS를 넘지 않기 때문에 SPI 클록은 50 MHz 이상의 속도에서 작동할 수 있다.
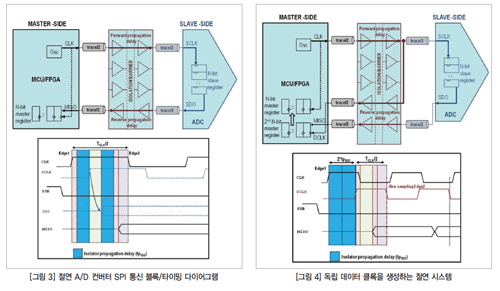
SPI 데이터 경로에 절연 장벽이 추가되면(그림 3) 전파 지연(propagation delay, tpISO), 또는 라인 지연(trace dealy)이 추가된다. 절연기 전파 지연은 사용된 절연 기술에 따라 100 nS를 넘을 수 있다. 그림3은 어떻게 추가된 절연기의 지연 시간이 데이터 트랜잭션에 필요한 시간과 최소로 요구되는 SPI 클록의 반주기(half period)를 매우 증가하는지 보여준다. 절연 지연은 시스템의 모든 시간 지연에 영향을 미치며 최고 클록 주파수는 몇 MHz로 떨어질 수 있다.
클록 주기에 대한 주요 제약은 데이터가 다음 클록 끝의 앞, 마스터에 반드시 존재해야 한다는 것이다. 비절연 시스템에서 이는 대단한 제약이 아니며 실제로 타이밍 여유를 충분히 둠으로써 데이터 전송의 안정성을 높인다. 하지만 일단 데이터 경로의 전파 지연이 반주기를 좌우하기 시작하면 버스의 최고 속도를 크게 낮춰서 절연기 전파 지연이 길어질 뿐 아니라 절연 시스템의 최대 쓰루-풋을 제한한다.
다행히 이러한 한계를 피할 방안이 있다. 슬레이브로부터 돌아오는 데이터가 그와 동기화된 독립 클록을 갖고 있다면 개별 수신 시프트 레지스터를 MCU에 설치해 개별 클록에 기반을 둬 데이터를 수용하도록 할 수 있다. 이 경우 SPI 버스의 쓰루풋은 절연 장벽의 전파 지연으로 인해 제한되는 일은 더 없으나 절연기의 쓰루풋 제약을 받는다.
개별 클록(DCLK)은 절연기에 데이터 채널을 하나 더하고 절연 SPI 클록을 복제해 보내면 간단히 생성된다(그림 4). ‘SPI 클록’ 경로의 절연기 지연은 ‘A/D 컨버터 데이터’ 경로에서의 절연기 지연과 대응해 절연기 지연이 최소로 요구되는 SPI 클록 주기를 제한하는 것을 효과적으로 방지한다.
그 대신 클록 주기는 그림 2에서 보듯이 더 짧은 지연에 의해서만 제약을 받으며 이는 시스템의 비절연 클록 주기에도 역시 제약을 준다. 따라서 이러한 접근 방법을 사용하면 SPI 클록이 더 빨라질 수 있지만, MCU에 추가적인 절연 채널 한 개와 독립된 클록의 시프트 레지스터를 추가해야 한다는 단점이 있다. MCU는 표준 SPI 레지스터보다 2차 수신 레지스터로부터 데이터를 읽어 들인다.
우리는 이러한 데이터 전송 방식이 다른 기술에서 어떻게 구현될 수 있는지를 설명하기 위해 다음 세 가지 예를 검토해 볼 텐데 이는 정량적인 방식에서 최대 속도, 정성적인 방식에서 전력 소비, 그리고 요구되는 보드 공간에 대한 예이다. 우리는 표준 절연 SPI에서 속도를 제한하는 것이 왕복 전파 지연이지만, 지연 클록 기법에서 한계를 만드는 것은 절연기의 시간 지연과 왜곡이라는 것을 보일 것이다.
광커플러 구현
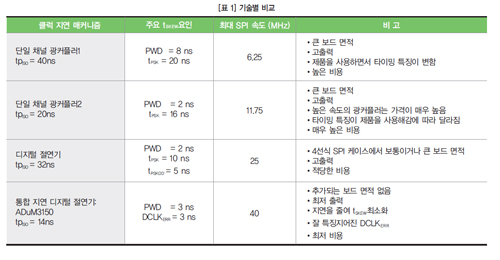
일반적인 산업 애플리케이션에서 단일 채널 디지털 광커플러는 주로 고속버스를 절연하는 데 사용된다. 표준 4선식 SPI 버스를 절연하는 데에는 광커플러 4대가 필요하다. 많이 사용되는 산업 CMOS 광커플러에서 최대 SPI 클록 속도를 추정하는 데 필요한 주요 타이밍 파라미터는 다음과 같다.
?12.5 MBPS의 최대 데이터율 또는 80 ns의 최소 펄스 폭.
?40 ns의 최대 전파 지연(tpISO).
?8 ns의 최대 펄스 폭 왜곡(PWD).
?20 ns의 최대 부품 간(part-to-part) 전파 지연 왜곡(tPSK). 이 파라미터는 다중 광커플러가 절연 SPI 버스를 생성하는 데 사용되기 때문에 중요하다.
SPI 쓰루풋을 추정하기 위해 그림 3에서 다른 부품에 대한 일반적인 지연 몇 가지를 가정한다. 각 라인 지연은 0.25 ns이고 총 라인 지연(tTRACE)은 1 ns라고 가정하자. 마찬가지로 슬레이브 지연(tSLAVE)과 마스터 설정 지연(tMASTER)은 각각 3 ns와 2 ns로 가정한다. 따라서 그림 3에서 절연 SPI 클록 속도를 논의하는 데 있어 위의 광커플러를 사용한 절연 SPI 버스에서 SPI 클록의 반주기는 [tTRACE+tSLAVE+ tMASTER+2*tpISO]ns 또는 86 ns 이상이므로 5.75 MHz의 최대 허용 SPI 클록 속도를 제공한다. 절연기 전파 지연이 길면 가능한 SPI 버스 속도를 크게 줄인다.
이제 절연 클록 신호를 마스터로 되돌려 보내고 그림 4에서 보듯이 지연 클록을 구현하기 위해 역방향으로 절연기를 추가한다고 생각해 보자. 이렇게 하면 슬레이브에서 데이터가 돌아오는 동시에 클록 신호를 생성할 수 있다. 절연기의 왕복 전파 지연[2*tpISO]은 더는 클록 속도를 제한하지 않는다. 시스템에 지연이 존재할 때 절연 SPI 클록의 반주기가 최소 [tTRACE+tSLAVE+tMASTER]ns 또는 6 ns가 되어서 80 MHz의 최대 SPI 클록 속도를 지원할 수 있는가? 불행히도 그에 대한 대답은 ‘그렇게 간단하지 않다’이다.
순방향 및 역방향 채널에서 비대칭은 그림 5에 나타난 최소 SPI 클록 주기를 tSKEW로 계산할 때 반드시 고려해야 한다. 부품 간의 전파 지연 왜곡과 펄스 폭 왜곡은 새로운 SPI 클록 반주기를 [tTRACE+tSLAVE+tMASTER+2*PWD+2*tPSK]ns 또는 62 ns로 제한한다. 이 때문에 실제 최대 클록 속도는 8 MHz가 된다. 하지만 80 ns의 최소 펄스 폭 제한 때문에 이 광커플러는 6.25 MHz의 최대 SPI 클록만 지원할 수 있다. 위의 예는 광커플러가 최소 펄스폭에 의해 제약을 받지 않더라도 tSKEW가 최대 SPI 클록 속도를 완벽히 지연 일치된 80 MHz정도부터 실제 애플리케이션에서는 6.25 MHz까지 크게 제한했다는 것을 보여준다.
더 짧은 최소 펄스폭을 가진 더 빠른 광커플러를 사용하면 도움이 될까? 20 ns의 최소 펄스폭을 지닌 초고속 광커플러를 사용하면 앞의 인터페이스를 더 빠른 속도에서 실행할 수 있다. 하지만 이러한 장치들에서도 지연과 왜곡 파라미터값이 크기 때문에 여러 가지 문제가 발생한다. tpSK가 16 ns, PWD가 2 ns이면 최소 SPI 클록의 반주기는 42 ns 이상이므로 최대 클록 속도는 11.75 MHz가 된다. 두 가지 경우 모두 시간이 지나면서 광커플러의 타이밍 특징이 한층 저하되기 때문에 지연 클록과 슬레이브 데이터 사이에 더 많은 불일치가 일어나게 된다. 이러한 차이를 위해 여유 타이밍을 추가하면 SPI 클록 속도는 더욱 줄어들게 된다.
SPI 절연을 위해 빠른 광커플러를 추가로 사용하면 높은 비용 외에도 차지하는 보드 면적도 메우 증가한다. 이러한 장치들은 보통 SO8 패키지의 단일 채널들로 구성되어 있으며 5개 채널이 필요하기 때문이다. 절연 인터페이스의 전력 예산(Power Budget)으로는 채널당 20 mA의 전류가 할당될 수 있다.
디지털 절연기 구현
지난 10년간 새로운 디지털 절연기 제품들이 출시됐다. 이 기기들은 집적도가 높고 속도가 빠르며 전파 지연, 지연 왜곡(Skew), 왜곡(Distortion)이 작다. 쿼드 채널 디지털 절연기를 생각해보자. 3개의 순방향 채널과 1개의 역방향 채널로 인해 4선식 SPI 버스로 된 소형 절연 방식이 가능해졌다. 광커플러의 예시와 마찬가지로 데이터시트에서 다음의 타이밍 파라미터를 살펴보자.
최소 펄스폭이 11.1 ns(90 MBPS), 최대 전파 지연(tpISO)이 32 ns, 최대 펄스폭 왜곡(PWD)이 2 ns, 부품 간 최대 전파 지연 왜곡(tpSK)이 10 ns이다. 하지만 단일 채널 광커플러와는 달리 쿼드 채널 디지털 절연기에서는 한 쌍의 반대 방향 채널 사이에 채널 간 일치를 고려할 필요가 있다. 위의 예에서 이 파라미터 값(tPSKOD)은 5 ns이다.
그림 3과 같은 일반 지연을 사용하면 디지털 절연기를 사용하는 절연 SPI 버스 클록의 반주기는 최소 [tTRACE+tSLAVE+tMASTER+2*tpISO]ns 또는 70 ns, 최대 클록은 7 MHz이어야 한다. 광커플러의 경우와 마찬가지로 SPI 속도가 절연기의 전파 지연으로 인해 크게 제약을 받는다는 것을 알고 있다. 하지만 표준 CMOS 기술로 만들어진 디지털 절연기는 제품 주기 전반에 걸쳐 안정적인 타이밍 특징을 보인다. 이 덕분에 우리는 타이밍 특징에 있어 변형을 위한 여분을 많이 두지 않고 SPI 클록 속도를 정할 수 있다.
지연 클록을 그림 4에서처럼 추가 절연기 채널과 함께 구현한다고 생각해보자. 최소한 고속 채널이 하나는 사용돼야 한다. 이렇게 하면 절연기의 전파 지연이 전반적인 SPI의 쓰루풋을 제한하는 것을 막고 SPI 클록은 클록과 데이터 채널 간의 불일치와 왜곡, 그리고 라인, 마스터, 슬레이브 지연에 의해서만 제한을 받기 때문에 클록 속도가 더 빨라질 수 있다. 모든 절연기 채널에서 타이밍이 비슷한 것을 고려하면 새로운 SPI 클록의 반주기는 최소 [tTRACE+tSLAVE+ tMASTER+2*PWD+tPSK+tPSKOD]ns 또는 25 ns, 최대 클록 속도는 20 MHz여야 한다.
많은 애플리케이션에서 MCU는 단순히 A/D 컨버터에서 데이터를 시프트-아웃할 뿐이고 어떤 것도 시프트-인 하지는 않는다. 그러한 3선식 SPI 버스에서 두 개의 역방향 채널을 가진 단일 쿼드 디지털 절연기는 SPI 버스와 지연 클록을 구현하는 데 사용할 수 있으며 이 경우 장점이 추가로 발생한다. SPI 클록의 반주기는 최소 [tTRACE+tSLAVE+ tMASTER+2*PWD+2*tPSKOD]ns 또는 20 ns여야 하므로 최대 클록 속도도 25 MHz로 더욱 빨라진다.
디지털 절연기의 속도와 왜곡이 광커플러보다 훨씬 나은 수준이지만 채널 간의 타이밍 지연과 왜곡은 여전히 가능한 최대 SPI 클럭 속도를 제한한다. 클록을 지연하기 위한 추가 절연기는 전력을 20 ~ 25% 더 많이 소비한다. 따라서 추가 절연기를 사용하면 전력 소모와 보드 공간이 늘어나는 반면 그로 인한 최대로 가능한 이점은 기대에 못 미친다.
디지털 절연기의 지연 클록 구현 최적화
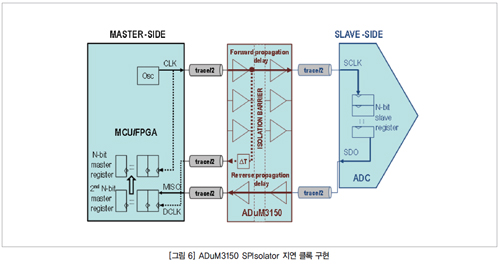
아나로그디바이스는 지연 클록 기법에서 가능한 최고의 성능을 제공하기 위해 최적화된 디지털 절연기를 개발해왔다. ADuM3150(그림 6)은 SPI 버스 절연을 최적화하기 위해 고안된 고속 디지털 절연기 제품군 일부이다.
ADuM3150는 추가 절연기 채널 없이 지연 클록(DCLK)을 생성한다. DCLK는 절연기를 통해 왕복 전파 지연[2*tpISO]에 해당하는 값만큼 표준 SPI 클록을 지연해 생성한다. 그림 6은 ADuM3150의 내부 블록 다이어그램을 보여준다. 지연 셀은 부품을 통해 왕복 전파 지연과 일치하도록 생산 시 주의해서 제거하므로 지연 클록과 돌아오는 슬레이브 데이터 간의 타이밍 불일치를 최소화한다. 지연 불일치가 많이 줄어들 뿐 아니라 광범위한 작동 환경에서 잘 정의되어 있으며 이는 데이터시트에서 DCLKERR 파라미터값을 통해 확인할 수 있다.
DCLKERR는 지연 클록이 슬레이브 데이터와 얼마나 동기화에서 멀어졌는지를 나타내는 지표이다. 따라서 DCLKERR 값은 지연 클록이 슬레이브 데이터보다 앞서는지 아니면 뒤처지는지를 알려준다. 지연 클록이 슬레이브 데이터를 샘플링해 마스터로 보내는 데 사용되기 때문에 지연 클록은 데이터를 앞서서는 안 된다. DCLK가 데이터보다 뒤처지는 것은 데이터 비트의 샘플링을 전부 놓치지 않는 한 허용할 수 있다.
ADuM3150 데이터시트에서는 DCLKERR가 -3 ns에서 8 ns 사이, PWD가 3 ns로 나타나 있다. 최대 선행 DCLK와 PWD을 충족시키려면 SPI 클록 속도는 최소 [tTRACE+tSLAVE+tMASTER+(min)|DCLKERR|+PWD]ns 또는 12 ns, 최대 클록 속도는 40 MHz이어야 한다. ADuM3150은 최대 40 MHz의 데이터율을 제공하고 추가 절연기 채널을 사용함으로써 발생할 수 있는 크기, 비용, 전력 소모의 증가 없이도 높은 SPI 클록 속도를 맞출 수 있다.
결론
센서 애플리케이션에서 오버샘플링이 동적 범위를 늘리는 데 도움이 되려면 해당하는 주파수와 비교해 샘플링 주파수를 높여 잡음을 크게 줄여야 한다. 이 글에서 등장한 지연 클록 기법은 절연 SPI 인터페이스의 쓰루풋을 향상하고 샘플레이트를 높이는 경로를 제공한다.
이 방법은 사용 가능한 절연 기술 전반에서 최대 SPI 클록 속도를 높이게 된다. 디지털 절연 기술은 채널 간 지연과 신호 체인의 기타 왜곡을 잘 관리하기 때문에 기존의 광커플러에 커다란 이점을 제공한다.
.jpg)
<저작권자(c)스마트앤컴퍼니. 무단전재-재배포금지>



